20万美元商业级视频生成大模型Open-Sora 2.0来了,权重、推理代码及训练流程全开源!
文章摘要
【关 键 词】 视频生成、开源模型、低成本、高效训练、技术突破
潞晨科技推出的 Open-Sora 2.0 是一款开源的 SOTA 视频生成模型,标志着视频生成领域的开源革命。该模型仅用 20 万美元(224 张 GPU)成功训练出商业级 11B 参数视频生成大模型,性能直追 HunyuanVideo 和 30B 参数的 Step-Video。在多项关键指标上,Open-Sora 2.0 与动辄数百万美元训练成本的闭源模型分庭抗礼,全面提升视频生成的可及性与可拓展性。此次发布全面开源模型权重、推理代码及分布式训练全流程,让高质量视频生成真正触手可及。
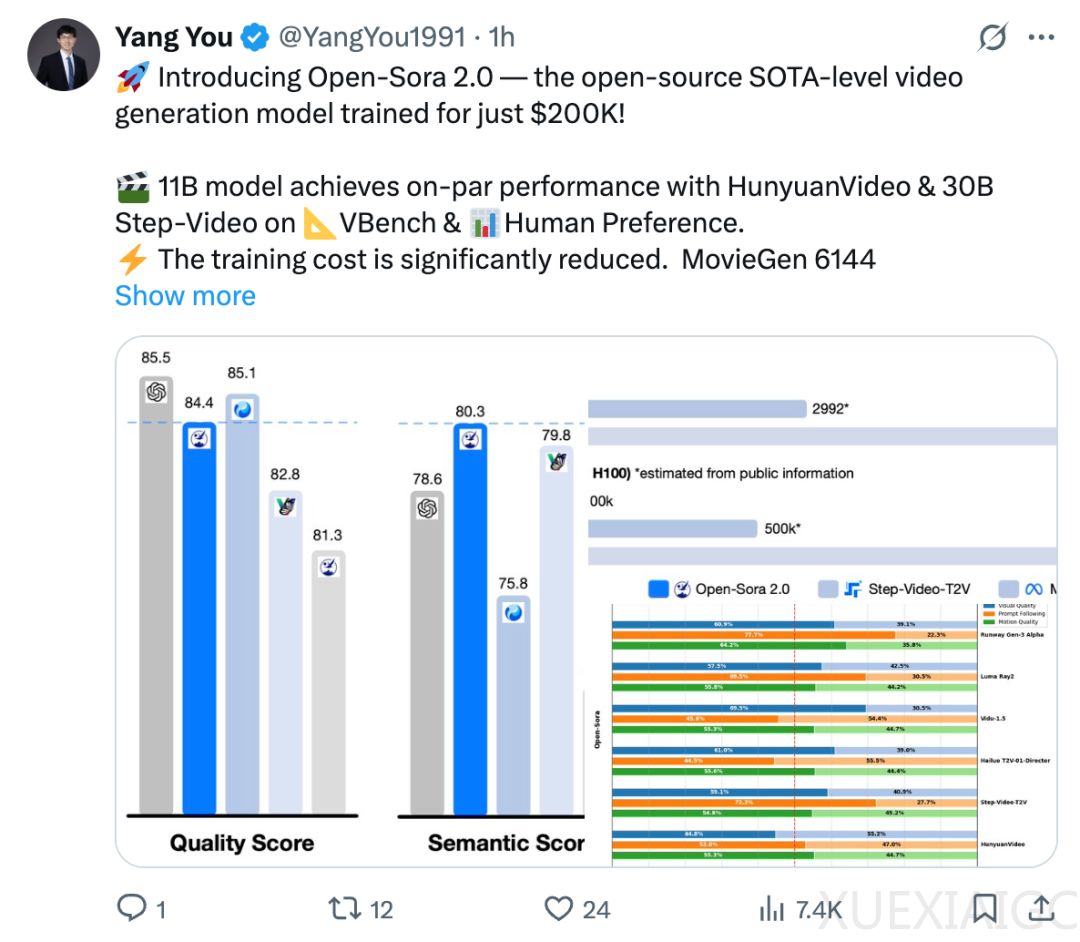
Open-Sora 2.0 在视觉表现、文本一致性和动作表现三个评估维度上,至少有两个指标超越了开源 SOTA HunyuanVideo 和商业模型 Runway Gen-3 Alpha。在 VBench 评测中,Open-Sora 2.0 的性能进步显著,与行业领先的 OpenAI Sora 闭源模型之间的性能差距从 4.52% 缩减至仅 0.69%,几乎实现了性能的全面追平。此外,Open-Sora 2.0 在 VBench 评测中取得的分数已超过腾讯的 HunyuanVideo,以更低的成本实现了更高的性能,为开源视频生成技术树立了全新标杆。
Open-Sora 2.0 的成功得益于其在模型架构和训练方法上的创新。模型采用 3D 自编码器和 Flow Matching 训练框架,并通过多桶训练机制,实现对不同视频长度和分辨率的同时训练。引入 3D 全注意力机制和 MMDiT 架构,更精准地捕捉文本信息与视频内容的关系,并将模型规模从 1B 扩展至 11B。此外,借助开源图生视频模型 FLUX 进行初始化,大幅降低训练成本,实现更高效的视频生成优化。
在训练方法上,Open-Sora 2.0 通过严格的数据筛选、多阶段多层次的筛选机制,确保高质量数据输入,从源头提升模型训练效率。优先将算力投入到低分辨率训练,以高效学习运动信息,在降低成本的同时确保模型能够捕捉关键的动态特征。同时,优先训练图生视频任务,以加速模型收敛。在推理阶段,除了直接进行文本生视频(T2V),还可以结合开源图像模型,通过文本生图再生视频(T2I2V),以获得更精细的视觉效果。
Open-Sora 2.0 还采用高效的并行训练方案,结合 ColossalAI 和系统级优化,大幅提升计算资源利用率,实现更高效的视频生成训练。这些优化措施协同作用,使 Open-Sora 2.0 在高性能与低成本之间取得最佳平衡,大大降低了高质量视频生成模型的训练。
在训练完成后,Open-Sora 2.0 进一步探索高压缩比视频自编码器的应用,以大幅降低推理成本。训练了一款高压缩比(4×32×32)的视频自编码器,将推理时间缩短至单卡 3 分钟以内,推理速度提升 10 倍。高压缩自编码器在训练视频生成模型时面临更高的数据需求和收敛难度,Open-Sora 提出了基于蒸馏的优化策略,以提升 AE(自编码器)特征空间的表达能力,并利用已经训练好的高质量模型作为初始化,减少训练所需的数据量和时间。
Open-Sora 2.0 的成功不仅在于其技术突破,更在于其开源生态的构建。作为开源视频生成领域的领导者,Open-Sora 不仅继续开源了模型代码和权重,更开源了全流程训练代码,成功打造了强大的开源生态圈。据第三方技术平台统计,Open-Sora 的学术论文引用量半年内获得近百引用,在全球开源影响力排名中稳居首位,领先所有开源的 I2V/T2V 视频生成项目,成为全球影响力最大的开源视频生成项目之一。
Open-Sora 2.0 的发布,标志着视频生成领域的开源革命,未来已来。让我们用更少的资源、更开放的生态,创造属于下一代的数字影像世界。
原文和模型
【原文链接】 阅读原文 [ 2454字 | 10分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章




