作者信息
【原文作者】 机器学习社区
【作者简介】 一个专注大模型、深度学习等前沿技术的技术号
【微 信 号】 ML_Community
文章摘要
【关 键 词】 RAG实现、Langchain、文档加载、文本嵌入、检索QA
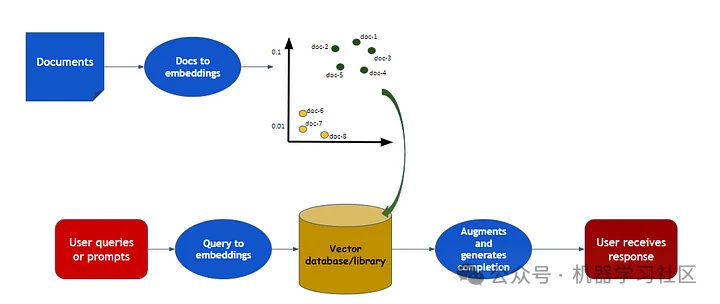
RAG(检索增强生成)是一种结合了大型语言模型(LLM)和特定数据集的技术,用于生成响应。本文介绍了如何使用Langchain和Hugging Face库在代码中实现RAG。
首先,需要安装一系列库,包括langchain、torch、transformers、sentence-transformers、datasets和faiss-cpu。这些库用于加载数据、处理文本、生成嵌入向量、存储向量以及构建问答模型。
文档加载阶段使用Hugging Face的数据集加载器,加载databricks-dolly-15k数据集。这个数据集包含多种类型的记录,如头脑风暴、分类、问答等。
接下来,使用文本拆分器将长文档拆分成小块,以便模型能够更有效地处理。在本例中,使用的是RecursiveCharacterTextSplitter,它通过递归地拆分文本来生成小块。
文本嵌入是通过预训练模型生成的,这里使用的是Hugging Face的嵌入模型。嵌入向量可以用于快速搜索相似的文本片段。
向量存储使用FAISS库来存储嵌入向量,并允许高效地搜索最相似的向量。这一步骤对于后续的检索和问答非常关键。
准备LLM模型时,选择了Intel/dynamic_tinybert模型,并使用Hugging Face的问答管道来处理文本和问题,生成答案。
检索器用于从数据库中返回与查询相关的文档。它依赖于向量存储来检索文档。
最后,使用RetrievalQA链结合了检索和问答步骤,以找到问题的答案。这个链使用了LLM模型和向量数据库作为检索器。
文章最后提到了使用开源模型可能遇到的挑战,如ValueError,以及如何通过LangChain使用OpenAI API。
总结来说,LangChain是一个强大的框架,用于构建与大型语言模型交互的应用程序,尤其适合那些需要针对特定文档提问或与自己的数据交流的场景。此外,还提到了一个AI算法交流群,这是一个技术沟通和求职交流的平台,覆盖了多个AI相关的领域。
原文信息
【原文链接】 阅读原文
【原文字数】 2546
【阅读时长】 9分钟

相关文章




