文章摘要
【关 键 词】 医疗大模型、临床评估、诊断生成、概率推理、性能比较
哈佛医学院联合多所研究机构通过OpenAI的o1-preview模型,系统评估了大语言模型在医疗推理任务中的实际能力。传统基于选择题的评估方式因无法反映真实临床决策复杂性而受到质疑,该研究通过设计多维度测试框架,由专家医师采用经过验证的测量方法进行质量评估,为医疗大模型的性能评估提供了新范式。
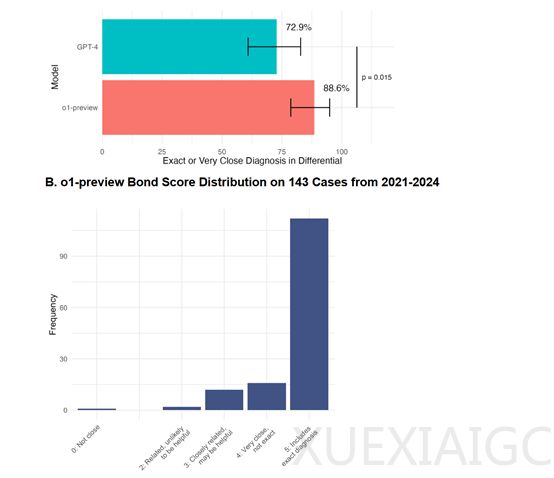
在诊断能力测试中,o1-preview在143个NEJM CPCs案例中实现了78.3%的正确诊断包含率,较GPT-4提升显著。当处理与GPT-4相同的70个案例时,其88.6%的确诊率较GPT-4的72.9%展现出明显优势。针对诊断测试计划评估,该模型在132个案例中87.5%选择正确测试方案,仅1.5%被判定为无帮助,证实了其临床决策支持的有效性。
研究团队采用Bond Score和Likert量表等标准化工具进行质量评估,通过双盲评分与Cohen’s kappa一致性检验确保结果可靠性。在R-IDEA评分体系中,o1-preview在80个虚拟患者案例中取得78个满分,远超GPT-4(47个)、主治医师(28个)和住院医师(16个)的表现,突显其在结构化临床推理方面的卓越能力。
管理决策测试显示,o1-preview在Grey Matters案例中的得分中位数达86%,较GPT-4(42%)和传统资源使用者(34%)具有显著优势。Landmark诊断案例比较中,其97%的中位数得分不仅超越使用GPT-4的医师(76%),更与GPT-4本身(92%)保持竞争力,验证了模型在复杂诊断场景中的稳定表现。
概率推理评估揭示,该模型在冠状动脉疾病压力测试中的概率估计更接近科学参考范围,尽管整体表现与GPT-4相近。研究采用混合效应模型等统计方法,证实o1-preview在多项指标上达到或超越人类专家水平。这些发现为医疗大模型在辅助诊断、临床决策支持和医学教育等场景的应用提供了实证依据,同时也为后续模型的优化方向提供了数据支撑。
原文和模型
【原文链接】 阅读原文 [ 1175字 | 5分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-r1
【摘要评分】 ★★☆☆☆


相关文章




