作者信息
【原文作者】 AI遇见云
【作者简介】 聚焦AI前沿技术 畅聊云上AI故事
【微 信 号】 ai_meets_cloud
文章摘要
【关 键 词】 语言模型、MoE网络、Mixtral 8x7B、大模型、技术特性
本文主要介绍了Mistral AI在2023年年底推出的以混合专家网络(MoE)为架构的大语言模型Mixtral 8x7B。该模型以其创新的网络架构和在总参数量更少的情况下性能媲美最先进的开源大模型Llama甚至GPT 3.5的优秀性能在大模型社区引起了广泛关注。文章详细分析了Mixtral模型的技术特性,并整理了最近社区的相关工作。
一、背景
MoE模型最早由Jacobs等人在1991年提出,旨在解决单一模型结构难以适应多样化数据和任务需求的局限性。MoE通过将多个“专家”集成在一起,每个专家负责学习数据的一部分,而“门控网络”负责协调这些专家。近年来,随着大规模语言模型的发展,MoE在NLP领域的应用变得更加广泛和深入。
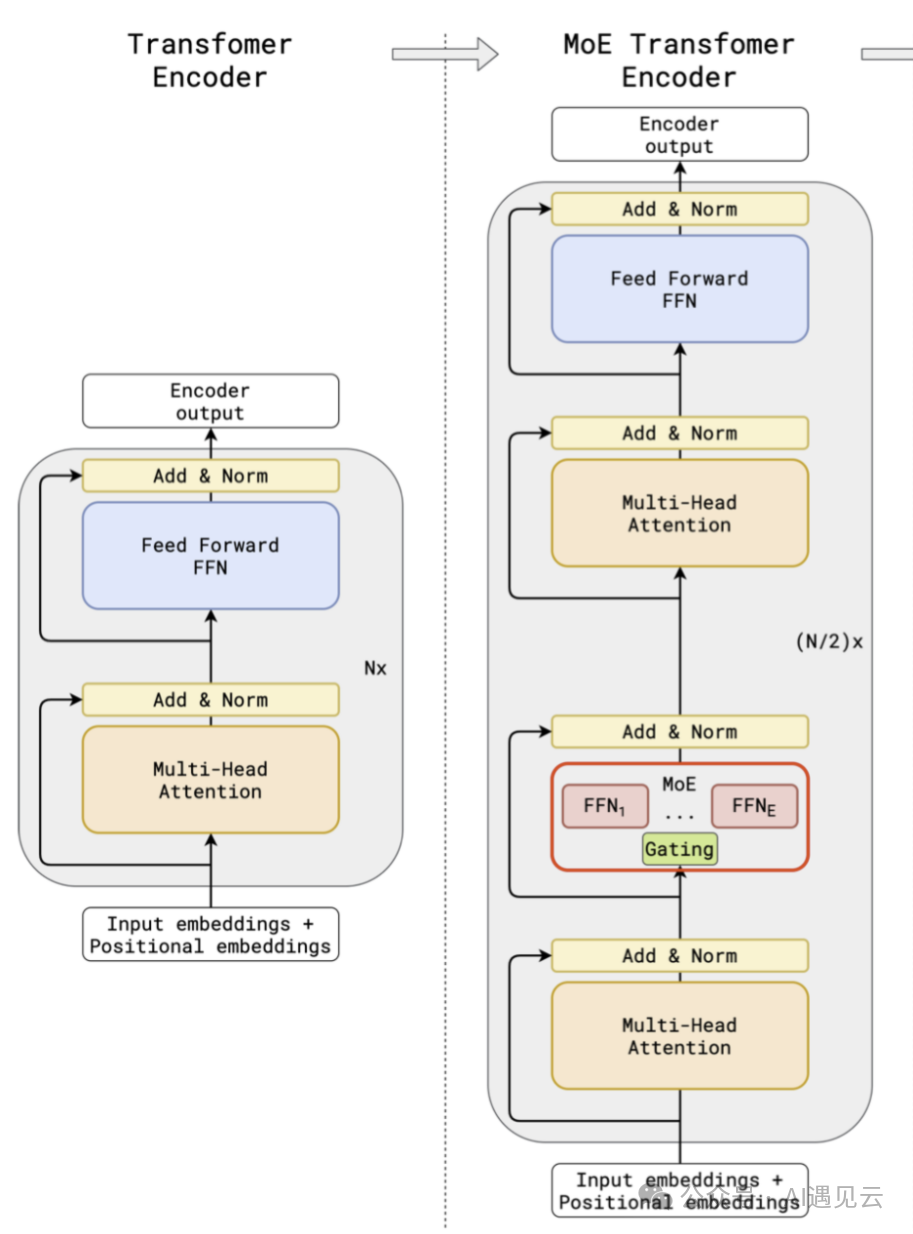
二、Mixtral MoE模型介绍
Mixtral 8x7B网络的实际总体参数量为47B,相较于总参数规模同量级的密集型网络(如Llama 70B),Mixtral MoE的预训练和推理效率更高。然而,Mixtral MoE网络的微调训练策略比密集型网络更加复杂。此外,MoE网络在推理阶段对显存的需求较大。
三、MoE网络的技术特性
MoE网络的核心思想来自于稀疏性,允许我们仅针对系统的特定部分执行计算。条件计算的概念使得在不增加额外计算负担的情况下扩展模型规模成为可能。然而,稀疏模型相对密集模型更容易在微调阶段陷入过拟合。
四、近期MoE的动态
随着Mixtral MoE模型的火爆,在大模型领域似乎兴起了一波“文艺复兴”。MoE这种似乎远离主流的模型设计又被重新拾起。许多研究团队已经基于Mixtral模型进行微调训练,发布了具有中英双语对话能力的模型。
五、总结
Mixtral 8x7B模型的推出,不仅展示了MoE架构在大模型领域的潜力,也为未来大模型底层结构提供了新的可能性。随着越来越多的研究和应用案例的出现,我们可以期待MoE模型在处理复杂任务和提升模型效率方面的进一步突破。
原文信息
【原文链接】 阅读原文
【原文字数】 2410
【阅读时长】 9分钟

相关文章




