MATRIX:社会模拟推动大模型价值自对齐,比GPT4更「体贴」
模型信息
【模型公司】 月之暗面
【模型名称】 moonshot-v1-32k
作者信息
【原文作者】 机器之心
【作者简介】 专业的人工智能媒体和产业服务平台
【微 信 号】 almosthuman2014
文章摘要
【关 键 词】 大语言模型、自我对齐、社会场景模拟、MATRIX框架、人类价值观
摘要总结:
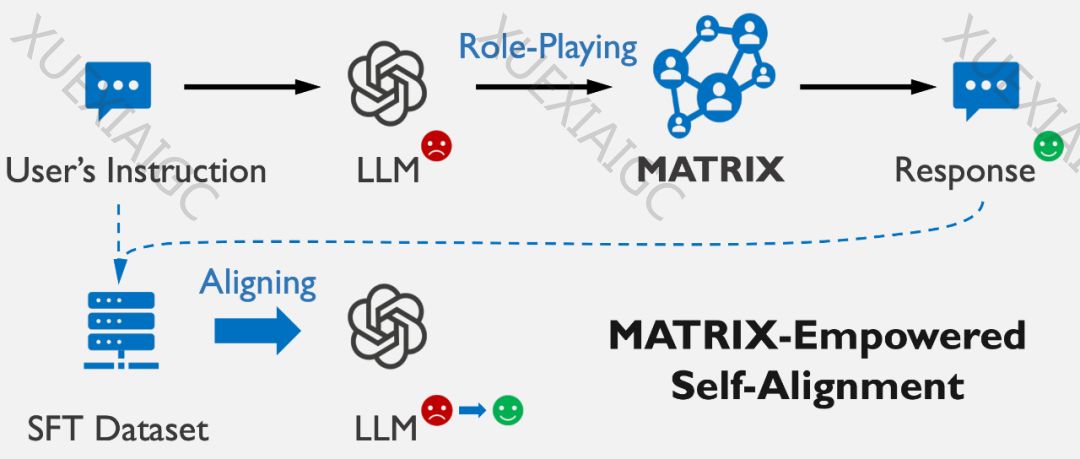
随着大语言模型(LLMs)的快速发展,如何确保它们与人类价值观对齐,避免社会负面影响成为一个重要议题。本文介绍了上海交通大学和上海人工智能实验室的科研团队提出的新研究——MATRIX框架,这是一种通过社会场景模拟实现LLM自我对齐的方法。
MATRIX框架的核心思想是通过模拟用户指令和LLM回答所涉及的社会场景,让模型观察到其回答可能造成的社会影响,从而理解并修正其行为。这种方法模仿了人类社会价值观的形成和发展机制,使LLM能够自我评估并修正可能产生负面社会影响的回答。
MATRIX框架包含社会角色、物体和社会调节器,支持逼真的社会模拟。LLM在模拟过程中扮演不同角色,体验社会反馈和影响,从而生成无害且负责任的回答。实验结果显示,MATRIX微调后的LLM在处理有害问题时,其回答质量超越了多种基线方法,甚至在真人测评中超越了GPT-4。
MATRIX框架的优势在于无需依赖外部资源,能够实现自我对齐,并通过监督微调(SFT)保持模型的响应速度。理论分析表明,MATRIX在泛化性与针对性的平衡上具有优势,能够为每个具体问题提供定制化的解决方案。
研究展望了MATRIX在自我对齐研究中的应用潜力,以及通过生成多样化的社会交互行为,促进对语言模型价值对齐的全面评测。同时,研究者期待MATRIX能够容纳更强大的代理,提升大语言模型在广泛任务中的表现。
重点内容加粗:
– 自我对齐策略:通过社会场景模拟,LLM能够自我评估并修正其行为。
– MATRIX框架:模拟社会互动及其后果,促进LLM生成与社会价值观对齐的回答。
– 实验结果:MATRIX微调后的LLM在处理有害问题时,回答质量超越了GPT-4。
– 理论优势:MATRIX在泛化性与针对性的平衡上优于预定义规则的方法。
– 未来展望:利用MATRIX生成多样化的社会交互行为,提升大语言模型的全面表现。
原文信息
【原文链接】 阅读原文
【原文字数】 2926
【阅读时长】 10分钟

相关文章





