RL训练总崩溃?R1-Reward稳定解锁奖励模型Long-Cot推理能力
文章摘要
【关 键 词】 多模态、强化学习、奖励模型、长时推理、稳定性
多模态奖励模型(MRMs)在多模态大语言模型(MLLMs)的性能提升中扮演着关键角色,尤其在训练和评估阶段能够提供稳定的奖励信号。然而,尽管强化学习(RL)在视觉任务和多模态推理任务中取得了显著进展,其在奖励建模中的应用仍面临诸多挑战,尤其是如何通过RL引入长期推理能力。来自快手、中科院、清华、南大的研究团队发现,直接将现有RL算法(如Reinforce++)应用于MRM训练时,训练过程极不稳定,甚至崩溃。为此,团队提出了一种新的算法——StableReinforce,旨在通过改进RL算法来稳定和提升MRM的长时推理能力。
StableReinforce算法通过Pre-CLIP策略和优势过滤器(Advantage Filter)显著提升了训练稳定性。Pre-CLIP策略在计算对数概率的指数值之前对比例进行裁剪,避免了由于比例差异过大而导致的数值溢出问题。优势过滤器则采用3-sigma规则,保留标准化优势在合理范围内的样本,防止极端值对训练的干扰。此外,团队还引入了一种“一致性奖励”(Consistency Reward),通过引入另一个大模型作为“裁判”,检查奖励模型的分析过程与最终答案是否一致,从而促使模型做出更符合逻辑的判断。
在训练策略上,团队采用了渐进式难度训练方法。首先,他们从公开数据集中收集了20万条偏好数据,构建了R1-Reward-200k数据集,并通过GPT-4o生成详细的思考过程作为监督微调(SFT)数据,帮助模型“入门”。随后,在RL阶段,团队专门挑选那些GPT-4o认为较难的样本进行训练,以提升模型在复杂任务中的表现。这种渐进式训练策略有效解决了RL训练中的冷启动问题,并显著提升了模型的推理能力。
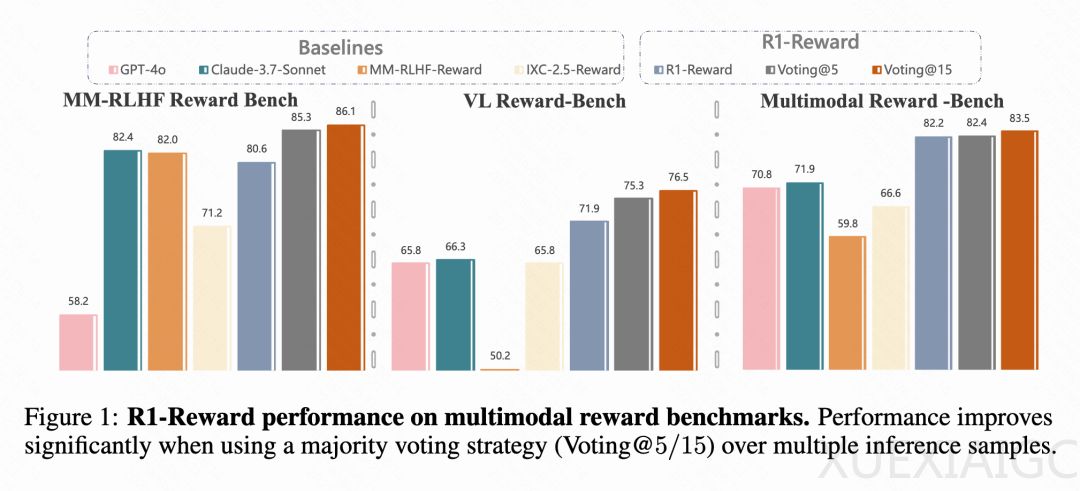
实验结果表明,R1-Reward在多个多模态奖励模型基准上表现优异,显著超越了现有最先进的模型(SOTA)。例如,在VL Reward-Bench和Multimodal Reward Bench等基准上,R1-Reward的准确率分别提升了8.4%和14.3%。此外,团队还发现,通过在推理时增加采样次数(如采样5次或15次),R1-Reward的性能还能进一步提升,这表明RL在优化奖励模型方面具有巨大潜力。值得注意的是,经过StableReinforce的RL训练后,模型输出的平均长度减少了约15%,表明模型的推理效率得到了提升。
R1-Reward不仅在学术上展现了巨大价值,还在快手的实际业务场景中得到了成功应用。例如,在短视频、电商和直播等场景中,R1-Reward已用于标签识别、多图/多视频相关性判断以及短视频推荐,并取得了显著的性能提升,展示了较强的工业化潜力。
总体而言,R1-Reward通过StableReinforce算法有效解决了MRM训练中的不稳定性和长时推理问题,显著提升了模型在多模态任务中的表现。未来,RL在奖励建模中的应用仍有广阔的研究空间,例如通过更先进的推理时扩展方法和改进的训练策略进一步提升模型性能。
原文和模型
【原文链接】 阅读原文 [ 4257字 | 18分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3/community
【摘要评分】 ★★★★★


相关文章



