OpenAI科学家姚顺雨:o3发布、RL迎来新范式,AI正式进入下半场
文章摘要
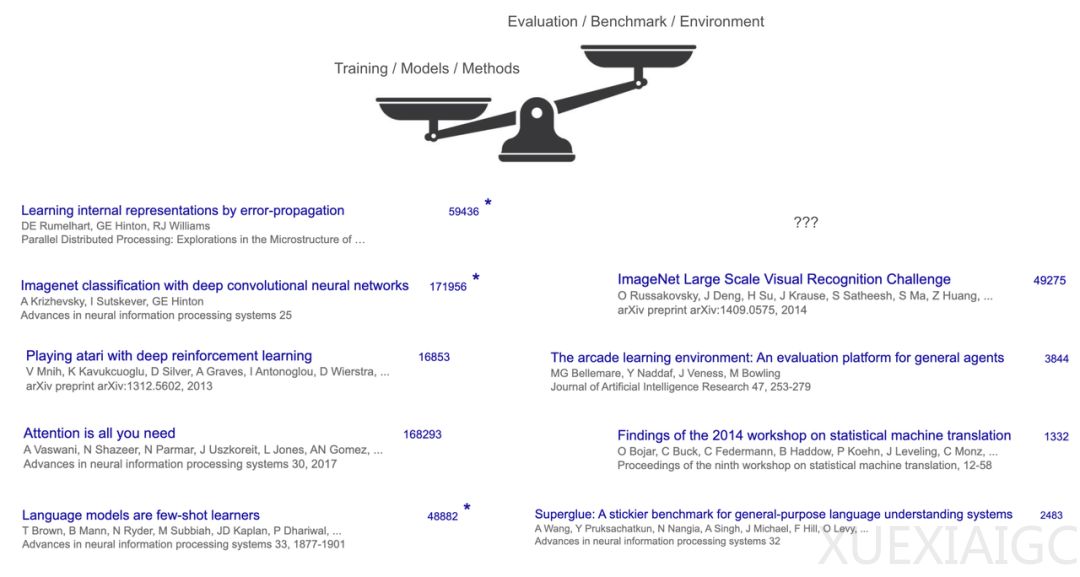
AI发展的“下半场”标志着从模型训练到问题定义和评估的转变。 过去几十年,AI的核心在于开发新的训练方法和模型,这一路径取得了显著成果,如AlphaGo和GPT-4等里程碑。然而,随着强化学习(RL)的泛化能力提升,AI的焦点逐渐从“解决问题”转向“定义问题”。在这一新阶段,模型评估(evaluation)比模型训练(training)更为重要,环境(environment)和先验知识(priors)的作用也被重新审视。
RL的崛起标志着AI进入了一个新的范式。 与预训练(pre-training)不同,RL通过与环境的交互生成新知识,尽管其算法和环境搭建更为复杂。OpenAI的研究表明,RL的成功不仅依赖于算法,还依赖于环境和先验知识。特别是,大规模的语言预训练为RL提供了必要的先验知识,使得模型能够在广泛的RL任务中表现出色。
AI上半场的成功主要归功于训练方法的创新。 例如,Transformer、AlexNet和GPT-3等模型通过新的训练方法在多个基准测试中取得了突破性进展。然而,这些模型的核心在于训练方法,而非任务定义或评估。随着RL的成熟,AI的焦点逐渐从训练方法转向任务定义和评估。这意味着未来的AI研究将更加关注如何定义任务和衡量进展,而不仅仅是开发新的训练方法。
AI的有效配方(recipe)包括大规模语言预训练、数据和算力的扩展、推理和行动的理念。 这一配方使得AI能够在多个领域表现出色,如软件工程、创意写作和数学问题等。然而,这一配方的成功也带来了新的挑战:如何设计更有效的评估方法,以推动AI的进一步发展。当前的评估方法往往基于独立同分布(i.i.d.)的假设,但现实世界中的任务往往是顺序进行的,这要求我们重新思考评估方法。
AI下半场的核心在于将智能转化为实际效用。 过去的AI研究主要集中在攻克电子游戏和标准化考试,而未来的研究将更加关注如何将AI应用于现实世界,创造出有用的产品。这一转变要求我们开发面向现实世界效用的全新评估设定和任务,并用现有的配方或新组件来攻克这些任务。这一过程充满挑战,但也为AI的未来发展提供了无限可能。
原文和模型
【原文链接】 阅读原文 [ 5810字 | 24分钟 ]
【原文作者】 Founder Park
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章




