文章摘要
【关 键 词】 强化微调、AI定制、效率提升、专业领域、推理能力
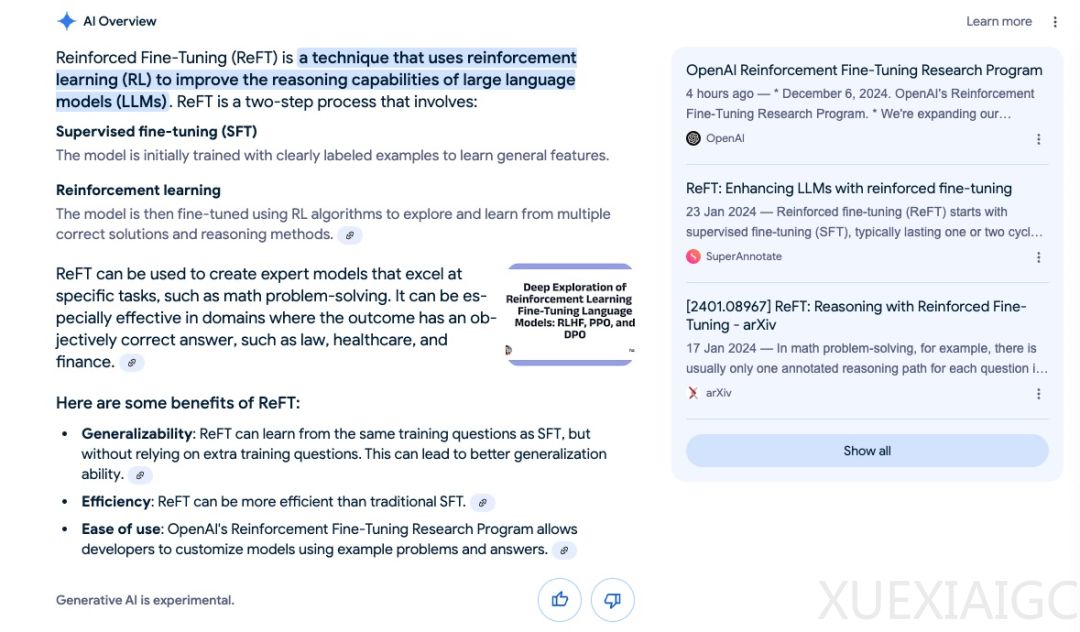
OpenAI在其“12天”活动的第二天发布了强化微调(Reinforcement Fine-Tuning)技术,并展示了ChatGPT Pro。这项技术允许企业用户通过极少的数据定制o1 mini模型,预示着AI模型定制化的重大突破。强化微调通过少量高质量示例快速调整模型推理方式,与需要大量特定领域数据的监督微调相比,更为高效。该技术工作原理是给予模型解决问题的空间,然后对答案进行评分,通过强化学习机制强化正确答案的思路,削弱错误答案的思路。
强化微调(ReFT)从监督微调(SFT)开始,通常持续一到两个周期,使模型获得基本能力。之后,ReFT通过强化学习算法如近端策略优化(PPO)提升模型训练水平,允许模型探索和学习正确的解决方案和推理方法。ReFT之所以高效,是因为它使用现有的训练数据,这些数据中已经包含了正确的答案,构成PPO训练过程中奖励的基础,无需额外的、单独训练的奖励系统。
OpenAI表示,基于强化微调,只需几十个示例,模型便能掌握在特定领域中以新的、有效方式进行推理的能力。实际上,只需12个例子就能做到这一点,这在常规的微调中是做不到的。强化微调的效果惊人,得分不仅比o1 mini高,而且还反超了昨天刚发布的o1版。
OpenAI CEO Sam Altman虽然未出现在直播中,但他在X平台上讨论了这一宣布,称新功能“效果惊人,是我2024年最大的惊喜之一”。科学家、开发人员和研究人员可以基于自己的数据定制强大的o1推理模型,而不再仅仅依赖公开可用的数据。各领域的从业者可以通过强化学习创建基于o1的专家模型,从而提升该领域的整体专业水平。这标志着AI定制化迈出了关键一步,使得AI模型能够在专业领域展现出更出色的表现。
在现场演示中,OpenAI研究员用伯克利实验室计算生物学家Justin Reese演示了强化微调如何大幅提高o1 mini的性能。具体来说,就是给定症状列表,让模型预测是哪个基因可能导致的遗传疾病。通过训练和验证数据集,模型能够从训练数据泛化到验证数据集,必须学会推理而不是仅仅记住症状列表。
最后评估生成的微调模型,以便可以看到它比开始使用的基础模型改进了多少。评分器功能很简单,就是获取模型的输出和正确答案,对其进行比较,然后返回一个介于0和1之间的分数。0表示模型根本没有得到正确答案,1表示模型得到了正确答案。测试中,OpenAI设置了三个不同模型的运行:第一个是针对昨天发布的o1模型,第二个是针对o1 mini,最后是强化微调后的o1 mini。可以看到,o1 mini在大约200个数据集上获得了17%的得分,o1做得更好,获得了25%,而微调后的o1 mini获得了31%的得分。
原文和模型
【原文链接】 阅读原文 [ 1931字 | 8分钟 ]
【原文作者】 AI前线
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★☆


相关文章



