文章摘要
【关 键 词】 图像生成、多模态模型、AIGC技术、模型训练、性能评估
AIGC领域的专业社区专注于微软、OpenAI、百度文心一言、讯飞星火等大型语言模型(LLM)的发展和应用落地,致力于LLM的市场研究和AIGC开发者生态建设。在图像生成领域,传统的文生图模型存在一定的局限性,如无法准确还原用户的提示词或生成特定形象的图像。
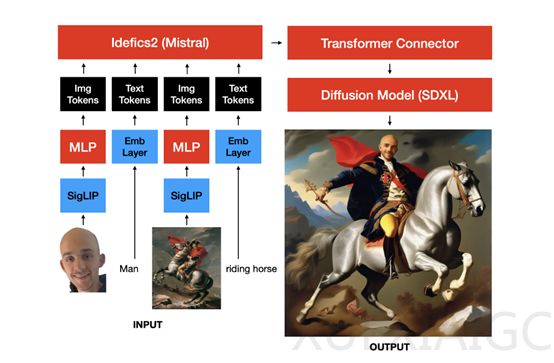
为了提高图像生成的准确度,Sutter Hill的研究人员开发了一种基于文本和图像引导的多模态图像生成模型MUMU。MUMU允许用户使用文本提示和参考图来生成目标图像,从而提升生成的准确率。MUMU的架构基于SDXL的预训练卷积UNet,通过替换SDXL的辅助CLIP文本编码器,并使用视觉语言模型Idefics2的隐藏状态构建。
Idefics2由一个视觉变换器、一个感知器变换器和一个大型视觉语言模型变换器组成。在MUMU架构中,研究人员去除了感知器变换器以使用更多的图像token,提高了图像质量。此外,还在Idefics2的隐藏状态之上添加了一个小型的非因果“适配器”变换器。
为了增强模型的能力,研究团队采用了合成数据和真实数据。合成数据由约300万张使用SDXL生成的图像组成,经过最低PickScore的筛选。为了鼓励模型区分内容和风格,每个内容都配对了许多不同的风格。同时,还使用了大语言模型从DiffusionDB中抽取内容和风格,并手动触发产生额外的内容和风格。
研究人员还加入了约200万张高质量的真实图像,主要包含人物。这些图像经过筛选,确保安全、高分辨率、无水印,并包含0或1个人物。随后,这些图像被中心裁剪到人物上,并使用Llava 1.6进行标题化处理。
在训练过程中,研究团队使用PyTorch FSDP在单个8xH100 GPU节点上分两个阶段训练MUMU。所有图像都用黑色像素填充为正方形分辨率,图像裁剪总是调整大小以满足目标分辨率。在第一阶段,每个提示最多插入四张图像,每张图像使用324个token,并插入最多三个在输入图像中检测到的对象的裁剪。30%的时间还会额外插入输入图像的canny边缘、深度或草图的图像。在第二阶段,每个提示插入一个对应1296个token的高分辨率人脸或人物裁剪,以观察更多token是否能改善人脸质量。
为了评估MUMU的性能,研究人员进行了一系列测试。与ChatGPT + DALLE-3的对比测试表明,MUMU在保留条件图像的细节方面表现更好。例如,当输入一张现实生活中的人像和一张卡通风格的图像时,MUMU能成功输出相同人物在卡通风格下的图像。此外,输入站立的人物和滑板时,MUMU能生成人物骑着滑板的画面。MUMU生成的图像能够更好地保留图像的细节,而ChatGPT + DALLE-3则相对较差。
总之,MUMU作为一种基于文本和图像引导的多模态图像生成模型,通过使用合成数据和真实数据以及分阶段训练,提高了图像生成的准确度和质量。在保留条件图像细节方面,MUMU相较于其他模型具有明显优势。这一研究成果为AIGC领域的图像生成技术提供了新的思路和方法。
原文和模型
【原文链接】 阅读原文 [ 1035字 | 5分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆


相关文章




