ICML 2024演讲爆火!Meta朱泽园揭秘大模型内心世界:不同于人类的2级推理
文章摘要
【关 键 词】 AIxiv专栏、学术研究、大语言模型、推理技能、模型错误
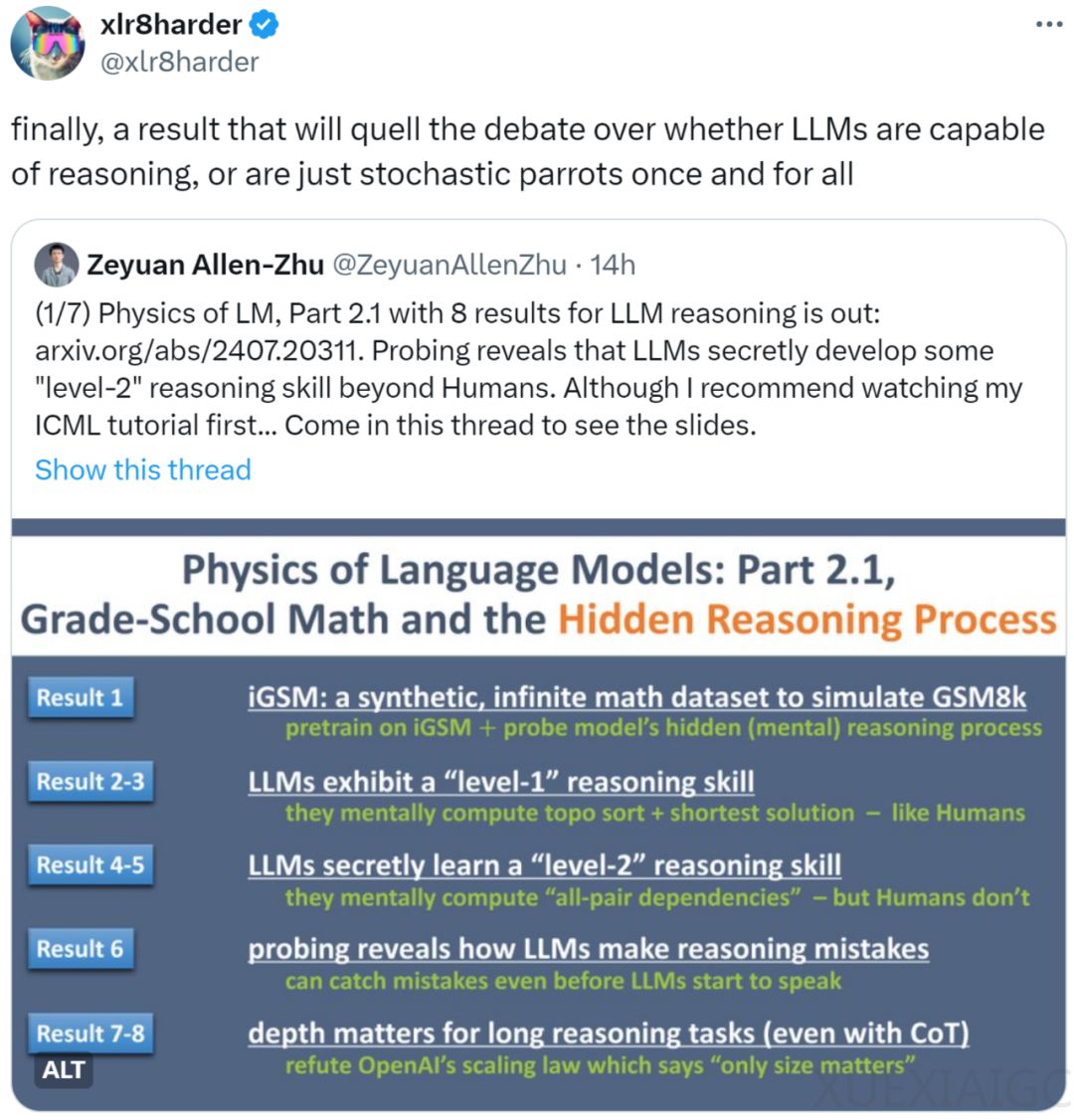
AIxiv专栏是一个由机器之心发布的学术和技术内容平台,近年来已经报道了2000多篇全球顶级高校和企业实验室的研究成果,促进了学术交流。近期,Meta FAIR、CMU和MBZUAI的研究人员叶添、徐子诚、李远志、朱泽园发表了一篇arXiv论文《语言模型物理学 Part 2.1:小学数学与隐藏的推理过程》,通过可控实验探讨了大语言模型(LLM)解数学题的机制。
论文首先指出,不能仅通过与大型模型如GPT-4的对话来推测其思维方式,而需要更严谨的科学方法来揭示模型的思考过程。研究者创建了iGSM数据集,一个模拟小学数学思维题集,让模型从零开始预训练,以控制模型接触的问题类型。iGSM数据集不包含常识信息,只包含mod 23范围内的加减乘,所有计算都使用CoT逐步进行。
通过iGSM数据集,研究者发现GPT2(RoPE版)在训练时能够达到99%的正确率,并且在更高难度的题目上也能保持83%的正确率,表明模型学会了推理技能。研究者进一步分析了模型的推理技能,发现模型能够进行0级推理和1级推理。0级推理是暴力计算,而1级推理是通过拓扑排序从问题开始反推,确定需要计算的变量。GPT-2能够学会1级推理,几乎每次都给出最短解答。
研究者还对模型的内部参数进行了探针研究,发现模型在生成第一句话之前已经通过心算确定了哪些变量是必要的,并且在说每句话之后也心算出了接下来所有可计算的变量。模型只需对必要和可计算的变量不断进行逻辑与运算,就能从叶子节点开始,一步步给出完整的计算过程。
此外,研究者发现模型还会心算许多对解题无用的信息,这种能力被称为2级推理。虽然2级推理对解题不必须,但它是一种更通用的技能,模型利用并行能力对信息进行大量因果梳理。这可能是通用人工智能中“通用”一词的潜在来源,即语言模型可以超越数据集所教的技能,学会更为通用的能力。
研究者还探讨了模型为何会犯错,发现模型在iGSM数据集上几乎只会犯两类错误:计算不必要的变量和计算当前不可算的变量。这些错误与模型生成过程中的随机性或beam search无关,而是系统性的,模型在生成第一个token之前就可以确信它会犯错。
论文还反驳了大模型缩放定律中强调的“唯大独尊”观点,即模型的表现只与参数数量相关,而与宽度或深度无关。通过iGSM数据集的可控实验,研究者发现对于解决iGSM中的数学题,模型的深度显然比宽度更为重要。对深度的依赖源于模型心算的复杂性,心算nece(A)往往需要更多层数。
最后,研究者指出,即使是GPT-4,在iGSM数据集上也只能进行最多10步的推理。这表明即使是当前最强的模型,利用了据称所有的互联网数据,仍无法精准地完成超过10步推理。这暗示现有大模型使用的预训练数据集可能还有很大的改进空间。通过本文的方法,建立人工合成数据来增强模型的推理能力以及信息梳理能力,或许是一种新的可能。
原文和模型
【原文链接】 阅读原文 [ 2729字 | 11分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章


