Gemini 2.0发布了,可惜的是关注的人很少
文章摘要
【关 键 词】 Gemini 2.0、AI模型、多模态、SynthID、实时交互
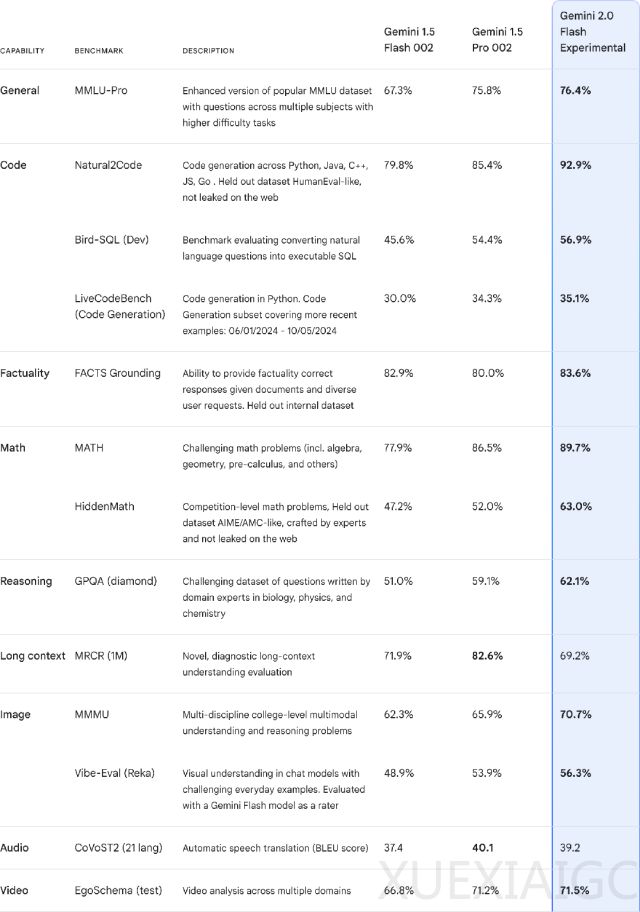
谷歌近日宣布推出其人工智能大模型系列的最新作品——Gemini 2.0,其中Gemini 2.0 Flash实验版本率先亮相。这款模型能够生成文本、图像和语音,并处理多种格式的输入,包括文本、图像、音频和视频,与GPT-4o等多模态AI模型相媲美。Gemini 2.0 Flash基于1.5 Flash的成功,性能和响应时间均有所提升,在关键基准测试中的表现甚至优于1.5 Pro,速度是1.5 Pro的两倍。
作为2.0系列中参数数量最小的模型,Gemini 2.0 Flash现已作为实验模型通过Google AI Studio和Vertex AI中的Gemini API向开发者提供。所有开发者均可使用多模式输入和文本输出,早期合作伙伴可使用文本转语音和原生图像生成功能。1月份将全面上市,同时将推出更多模型尺寸。谷歌计划将该技术集成到Android Studio、Chrome DevTools和Firebase等产品中。
为解决生成内容的潜在滥用问题,谷歌将在所有由Gemini 2.0 Flash创建的音频和图像上添加SynthID水印技术。谷歌CEO Sundar Pichai表示,谷歌一直在投资开发更多的代理模型,这些模型可以更多地了解周围的世界,提前思考多个步骤,并在监督下代表用户采取行动。
除了Gemini 2.0 Flash,谷歌还公布了几个研究项目,展示了Gemini 2.0 Flash在具体情境中的功能。Project Astra是一款Android手机视觉AI助手原型,现已更新,可以处理多种语言、使用谷歌搜索和地图,并记住长达10分钟的对话。谷歌正在与游戏开发商Supercell合作创建能够理解游戏玩法并提供实时建议的”AI代理”。Project Mariner是一个Chrome扩展原型,通过理解屏幕内容和浏览器元素,帮助用户以代理的方式完成基于网络的任务。谷歌还推出了名为Jules的实验性人工智能编程代理,能够在GitHub的工作流程中发挥作用,协助开发人员规划和执行编程任务。
此外,谷歌还推出了全新的Multimodal Live API,支持创建集成实时音频和视频流的应用程序。这款API能够与外部工具无缝集成,处理中断等自然对话模式,为用户提供更加流畅和自然的交互体验。谷歌强调Gemini 2.0仍在开发中,随着时间的推移,可能会陆续推出更新、更大的模型和增强功能。
原文和模型
【原文链接】 阅读原文 [ 1011字 | 5分钟 ]
【原文作者】 AI大模型实验室
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆


相关文章




