文章摘要
【关 键 词】 GPT-4o mini、Claude 3.5 Sonnet、竞技场、大模型、评分
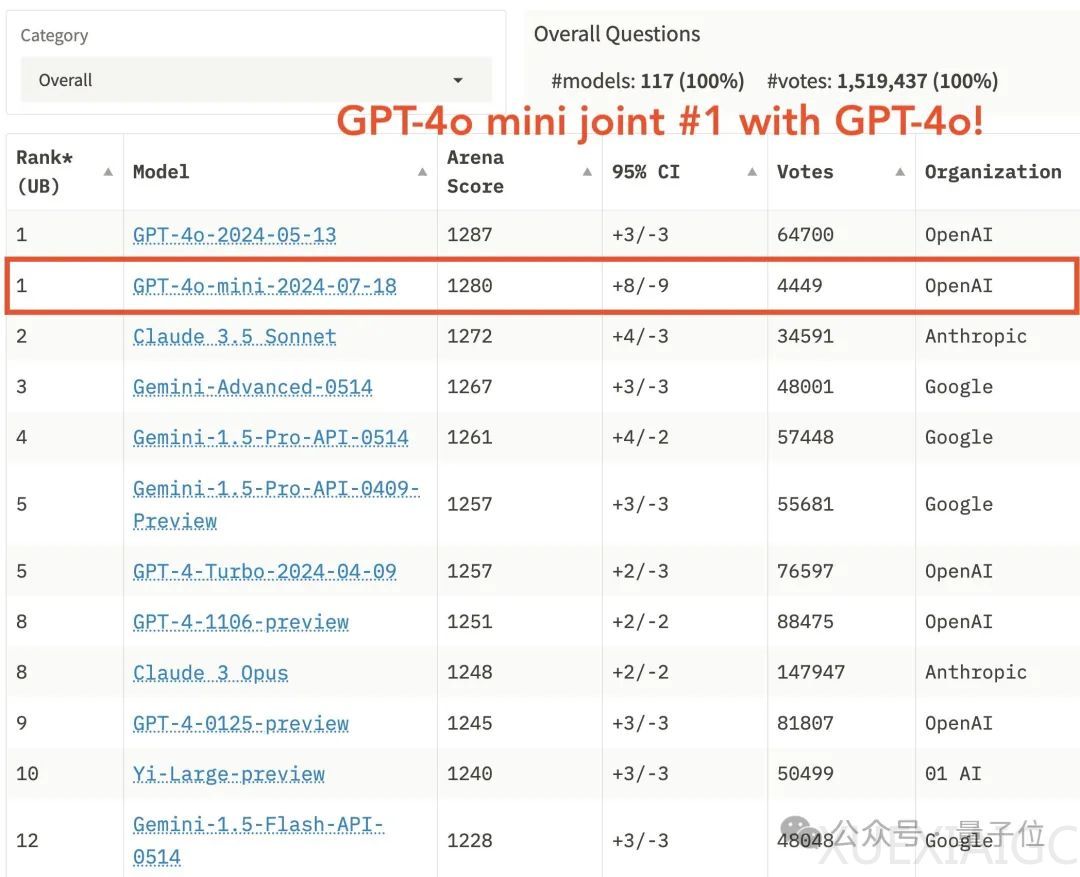
在lmsys竞技场公布的榜单中,GPT-4o mini与满血版并列第一,引发了广泛争议。许多人质疑这一结果,认为lmsys可能受到了OpenAI的影响。然而,官方随后公布了GPT-4o mini参与的1000场battle的完整数据,包括不同语言和不同模型的PK情况,让所有人能够查看这些结果。
经过仔细分析,人们发现GPT-4o mini能够战胜Claude 3.5 Sonnet,主要依靠三大关键因素:1) 拒绝回答次数更少;2) 更详细的回答,总是愿意提供额外信息;3) 回答格式更清晰明了。这些因素使得GPT-4o mini在竞技场中更容易获得裁判的青睐。
例如,在面对一些特定问题时,GPT-4o mini的回答长度通常是Claude 3.5 Sonnet的两倍,且更愿意从公开资料中搜集信息,而不是直接拒绝回答。此外,GPT-4o mini在回答中使用了更多的小标题和加粗格式,使得整个回答更加一目了然,易于理解。
然而,GPT-4o mini在数学任务上的表现相对较差,且记忆力不如Claude。在某些情况下,Claude能够一次修复的bug,GPT-4o mini可能需要20次尝试和1小时的时间。尽管如此,在竞技场评分中,GPT-4o mini仍然位居前列。
这一现象引发了人们对于大模型拒答问题的思考。一些人认为,过高的道德边界可能导致大模型在评分中得分不高。为了更好地利用这些道德感强的大模型,用户需要精心设计每一个提示词,这无疑增加了使用难度。
总的来说,GPT-4o mini和Claude 3.5 Sonnet各有优缺点。GPT-4o mini更愿意接受不同需求,回答更详细,格式更清晰,因此在竞技场中更受欢迎。而Claude 3.5 Sonnet则更严谨,按照要求行事,但在某些情况下可能会因为拒绝回答而失去分数。这一对比反映出大模型竞技场的特点,即大部分用户提出的问题都比较日常,而非复杂的数学、推理或编程问题。在这种情况下,通过不拒绝回答或以更漂亮的格式呈现,确实可以更好地俘获裁判的芳心。
原文和模型
【原文链接】 阅读原文 [ 1342字 | 6分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章




