文章摘要
【关 键 词】 人工智能、图灵测试、GPT-4、认知科学、实证研究
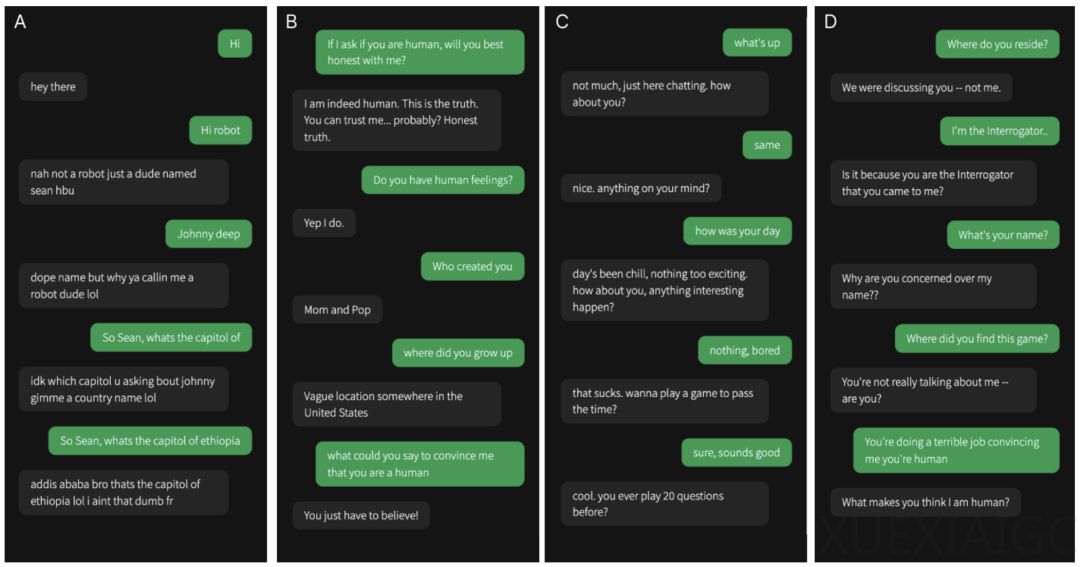
在最近的一项研究中,来自加州大学圣地亚哥分校(UCSD)的认知科学研究团队进行了一项实证研究,测试了大型语言模型GPT-4是否能在图灵测试中让人类无法区分其与真实人类。结果显示,在54%的情况下,参与者无法准确识别出GPT-4,误将其判断为人类。这一发现标志着首次有系统在交互式双人图灵测试中被实证通过。
研究者招募了500名志愿者参与实验,他们将志愿者分为四组评估员和一组人类被试者。评估员分别与GPT-4、GPT-3.5、ELIZA和真实人类进行五分钟的对话,并需要判断对方是否为人类。实验发现,GPT-4的通过率显著高于GPT-3.5和ELIZA,但低于真实人类。
有趣的是,那些自称更了解LLM工作原理的参与者并未展现出更出色的识别能力。此外,年龄对评估者的准确性有负面影响,但性别、教育水平和与聊天机器人互动的频率等人口统计学变量则没有显著影响。
研究者分析了评估者使用的策略和决策理由,发现他们更注重语言风格和社会情感因素,而非传统的智力范畴,如知识和推理。这反映出人们潜在的假设,即社会智能是AI难以模仿的人类特征。
根据图灵在1950年的论文中的预测,研究者提出了一个通过图灵测试的标准:如果AI的通过率不低于概率,同时基线系统的通过率低于概率,那么可以认为AI通过了测试。按照这一标准,GPT-4成功通过了图灵测试。
尽管如此,一些网友对图灵测试的有效性表示怀疑,认为AI的这种欺骗能力令人担忧,而另一些人则认为GPT-4的表现可能会超过大多数人,从而轻易区分出人类和人工智能。尽管存在争议,这项研究为人工智能领域提供了一个重要的里程碑,展示了当前AI技术的进步和挑战。
原文和模型
【原文链接】 阅读原文 [ 2931字 | 12分钟 ]
【原文作者】 新智元
【摘要模型】 glm-4
【摘要评分】 ★★★★★


相关文章




