文章摘要
【关 键 词】 AI软件工程师、Devin、DevBench、编程能力、软件开发
DevBench团队最近推出了首个AI软件工程师Devin,它的能力在技术界引起了广泛关注。
Devin不仅能够解决编码任务,还能独立完成软件开发的整个周期,包括项目规划、BUG修复、AI模型训练和微调等。
在SWE-Bench基准测试中,Devin以13.86%的问题解决率遥遥领先,远超GPT-4的1.74%得分,显示出其卓越的软件开发能力。
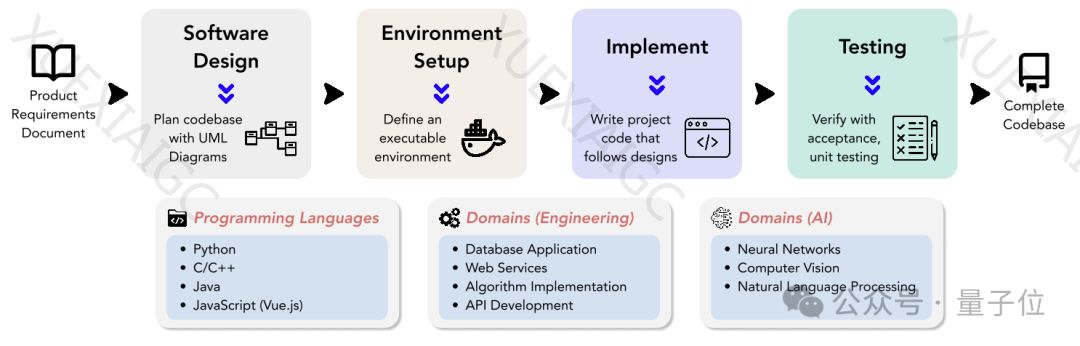
上海人工智能实验室、字节跳动SE Lab和SWE-Bench团队共同提出了新的测试基准DevBench,旨在评估AI大模型在软件开发各阶段的能力。
DevBench涵盖了从产品需求文档到完整项目开发的评测,包括软件设计、环境设置、代码实现、集成测试和单元测试等关键任务。
测试结果揭示了大语言模型在面向对象编程、构建脚本编写和函数调用参数匹配等方面的短板。
DevBench的数据集包含4种编程语言、多个领域的22个代码库,为语言模型提供了丰富的挑战。
例如,TextCNN项目要求模型能够处理文本分类、超参数定制和实验可复现性;前端项目Registration & Login考验模型在版本冲突中的应对能力;People Management项目测试模型对SQLite数据库的管理能力;Actor Relationship Game项目需要模型构建演员之间的人际网络;ArXiv digest项目则是开发论文检索工具。
DevBench的实验发现,尽管当前流行的LLMs在简单编程任务中表现良好,但在复杂的软件开发挑战面前,它们的性能仍有待提高。
DevBench不仅揭示了LLMs的局限性,也为未来模型的改进提供了洞见。
此外,DevBench的开放性和可扩展性意味着它可以适配不同的编程语言和开发场景,并鼓励社区参与共建。
DevBench已加入OpenCompass大模型评测体系,这是上海人工智能实验室推出的一站式评测平台,具有可复现性、全面的能力维度、丰富的模型支持等特点。
DevBench的加入进一步拓宽了OpenCompass在智能体领域的评测能力。
随着AI软件开发能力的持续发展,Devin在SWE-Bench上的领先表现是否能扩展到其他评测场景,这场码农和AI的较量令人期待。
DevBench的论文和代码已在arXiv和GitHub上公开发布。
原文和模型
【原文链接】 阅读原文 [ 2209字 | 9分钟 ]
【原文作者】 量子位
【摘要模型】 gpt-4
【摘要评分】 ★★★★☆


相关文章



