GPT超越扩散、视觉生成Scaling Law时刻!北大&字节提出VAR范式
文章摘要
【关 键 词】 VAR、图像生成、自回归模型、扩散模型、Scaling Laws
机器之心最近发布了一篇关于新一代视觉生成范式「VAR: Visual Auto Regressive」的文章,这一新工作由北京大学和字节跳动的研究者提出,已经引起了广泛关注。
VAR模型在图像生成方面首次超越了扩散模型,并展现出了与大型语言模型类似的缩放定律和零样本任务泛化能力。
VAR模型的核心思想是模仿人类处理图像的逻辑顺序,即从整体到细节的多尺度顺序逐渐生成token map。这种方法不仅更符合人类直觉,而且大幅提高了生成速度。VAR模型的训练分为两个阶段:首先是多尺度量化自动编码器(Multi-scale VQVAE)的训练,然后是与GPT-2结构一致的自回归Transformer的训练。VAR模型在实验中展现出了比传统自回归模型更强的性能和缩放能力。
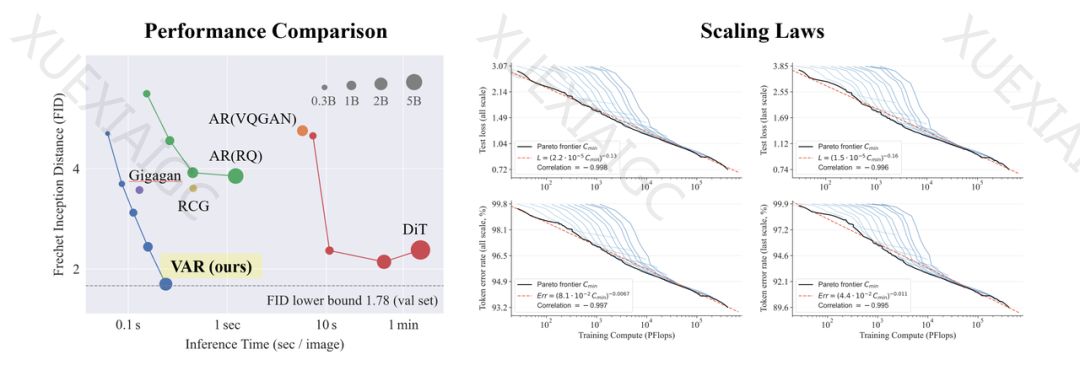
在Conditional ImageNet 256×256和512×512的实验中,VAR模型不仅提升了自回归模型的效果,而且在生成速度上大幅超过了自回归和扩散模型,甚至接近了GAN的高效率。VAR模型在扩展到2B/3B参数时达到了SOTA水平,展现出了一个全新的、有潜力的生成模型家族。与SORA、Stable Diffusion 3的基石模型Diffusion Transformer(DiT)相比,VAR在效果、速度和缩放能力上都展现出了更好的表现。
研究者还对VAR模型的缩放定律进行了实验,发现VAR展现出了与大型语言模型几乎完全一致的幂律缩放定律。这表明VAR模型的生成能力随着模型参数量、训练token个数和计算开销的增长而逐步提升。此外,VAR模型还展现出了一定的零样本任务泛化能力,在没有任何微调的情况下,就能够泛化到图像补全、图像外插和图像编辑等生成式任务中。
总结来说,VAR模型为图像自回归顺序提供了一个全新的视角,即由粗到细、由全局轮廓到局部精调的顺序。这种方法不仅符合直觉,而且在多方面使得自回归模型首次超越了扩散模型。VAR模型的缩放定律和零样本泛化能力也显示了其潜力。作者们希望VAR的思想、实验结论和开源能够促进社区探索自回归范式在图像生成领域的使用,并推动基于自回归的统一多模态算法的发展。
原文和模型
【原文链接】 阅读原文 [ 2148字 | 9分钟 ]
【原文作者】 机器之心
【摘要模型】 gpt-4
【摘要评分】 ★★★★★


相关文章




