模型信息
【模型公司】 月之暗面
【模型名称】 moonshot-v1-32k
【摘要评分】 ★★★★★
文章摘要
【关 键 词】 Fine-tuning、深度学习、机器学习、模型微调、强化学习
摘要总结:
本文介绍了深度学习和机器学习中的一个重要概念——Fine-tuning(模型微调)。Fine-tuning通常在预训练模型的基础上进行,通过在特定任务的数据集上进一步训练来调整模型参数,以提高模型在特定任务上的性能。这种方法尤其适用于数据量不足以从头开始训练大型模型的情况。
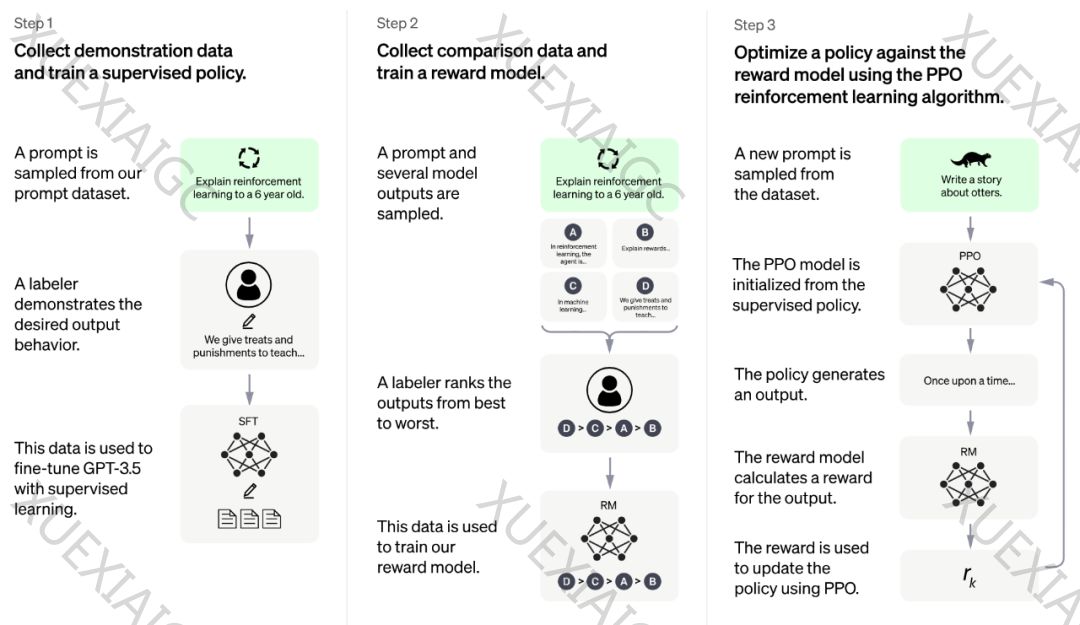
文章首先解释了什么是Fine-tuning,然后详细介绍了OpenAI GPT-3.5模型的强化学习微调过程,分为三个步骤:收集示范数据并训练监督策略、收集比较数据并训练奖励模型、使用PPO强化学习算法对策略进行优化。这个过程涉及到迭代的人类反馈强化学习(RLHF),目的是使模型生成的文本质量逐步提升,更符合人类的偏好。
接着,文章提到了Alpaca项目,它使用GPT的输出数据作为训练数据,在LLaMA 7b模型上进行Fine-tuning,以低成本取得了接近GPT-3.5的效果。此外,还提到了Hugging Face训练框架,它可以用于对LLaMA模型进行微调。
最后,文章给出了在垂直领域进行Fine-tuning的最佳实践方式,包括准备高质量的prompt数据集、选取开源模型进行Fine-tuning训练和本地私有化部署、对输出结果进行标记排序等步骤。
文章强调了在Fine-tuning过程中需要注意的细节,并承诺将在后续文章中继续深入讨论。同时,作者邀请读者加入知识星球“极客e家”,共同打造极客文化。
原文信息
【原文链接】 阅读原文
【阅读预估】 2010 / 9分钟
【原文作者】 极客e家
【作者简介】 聚焦技术发展趋势和行业最新动态,定期分享优质的技术文章和工具,让您在极客文化的熏陶中有所收获,助您走向技术大牛之路。

相关文章





