文章摘要
【关 键 词】 AI创新、DeepSeek、多模态、图像理解、全球竞争
春节之际,AI公司DeepSeek(深度求索)以其创新的AI模型在全球科技圈引起震动。1月20日,DeepSeek发布了推理模型DeepSeek-R1正式版,该模型以低成本训练出的性能媲美OpenAI的推理模型o1,且完全免费开源,引发行业关注。这一成就不仅使DeepSeek的移动端应用迅速登顶美区苹果应用商店免费App排行第一,超越了ChatGPT等热门应用,还直接影响了美股,尤其是英伟达的股价。
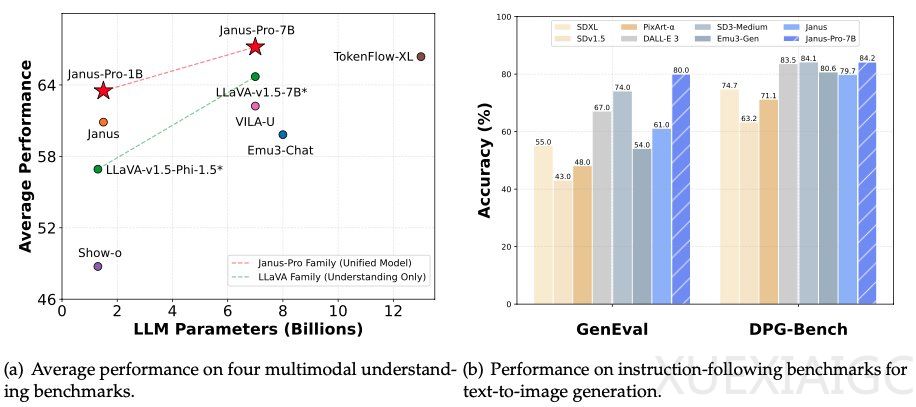
1月28日,DeepSeek进一步开源了其多模态模型Janus-Pro-7B,并宣布在GenEval和DPG-Bench基准测试中击败了DALL-E 3和Stable Diffusion。Janus-Pro-7B和Janus-Pro-1B(1.5B参数量)是Janus模型的升级版,采用了创新架构,对理解(图生文)和生成任务(文生图)的视觉编码进行解耦,提升了模型训练的灵活性,有效缓解了性能瓶颈。Janus系列模型展现出强大的指令跟随能力、多语言能力和理解复杂图像的能力。
DeepSeek还发布了Janus Flow新型多模态AI框架,旨在统一图像理解与生成任务。Janus Pro模型能够提供更稳定的输出,具有更好的视觉质量、更丰富的细节以及生成简单文本的能力。模型既能生成图像,也能对图片进行描述,识别地标景点,识别图像中的文字,并能对图片中的知识进行介绍。
Janus-Pro模型在多模态理解任务中采用SigLIP-L作为视觉编码器,支持384 x 384像素的图像输入。在图像生成任务中,使用特定来源的分词器,降采样率为16。尽管图像规模尺寸较小,但Janus Pro模型在架构和参数量上的创新意义重大。特别是Janus Pro的1B模型,仅使用15亿参数,已能在WebGPU上的浏览器中100%运行,预示着图片生成/图片理解的成本进一步下降,AI的使用将更加普及。
DeepSeek的成功展示了中国AI在全球的竞争力,其低成本高效率的模型开发能力让美国同行感到压力。2025年,中国AI有望进一步冲击美国的认知,DeepSeek的创新和秘密将继续引领AI领域的发展。
原文和模型
【原文链接】 阅读原文 [ 2057字 | 9分钟 ]
【原文作者】 极客公园
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




