DeepSeek-V3外网刷屏爆火,训练成本只有600万,把AI大佬都炸出来了
文章摘要
【关 键 词】 MoE模型、低成本、开源SOTA、训练效率、负载均衡
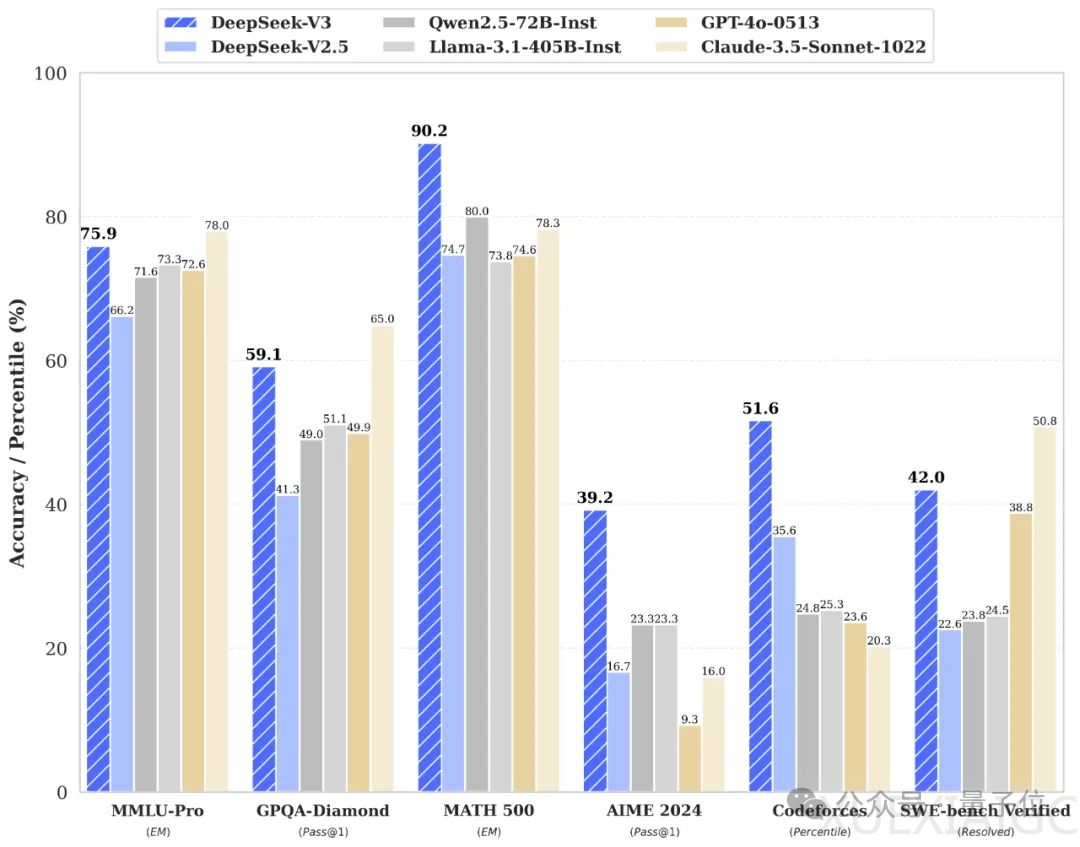
DeepSeek V3是一款参数量为671B的MoE模型,激活37B,在14.8T高质量token上进行了预训练。该模型以其低成本和开源特性受到关注,其训练细节在53页的论文中被详细披露。DeepSeek V3在多项测评中达到了开源SOTA,超越了Llama 3.1 405B,并能与GPT-4o、Claude 3.5 Sonnet等顶级模型竞争,同时价格仅为Claude 3.5 Sonnet的9%。
DeepSeek V3的训练成本仅为557.6万美元,远低于Llama 2的76万美元。OpenAI创始成员Karpathy和Meta科学家田渊栋均对DeepSeek V3的训练效率和效果表示赞赏。贾扬清强调了分布式推理时代的到来,并指出MoE模型负载均衡的重要性。DeepSeek V3在评测中不仅超越了其他开源模型,甚至与一些顶尖闭源模型不相上下,同时生成速度提升了3倍,每秒能生成60个tokens。
DeepSeek V3的API价格具有竞争力,每百万输入tokens价格为0.5元(缓存命中)/2元(缓存未命中),每百万输出tokens价格为8元,成为性价比极高的选择。在搜索产品Kagi的评测中,V3也表现出色,紧随Sonnet-3.5与GPT-4o之后。
DeepSeek V3的预训练细节显示,通过算法、框架和硬件的协同优化,训练成本得到有效控制。预训练阶段,每万亿token的训练仅需18万GPU小时,官方2048卡集群上3.7天即可完成训练。研发团队在不到2个月内完成了DeepSeek V3的预训练,总训练成本为278.8万GPU小时。
DeepSeek V3的MoE由256个路由专家和1个共享专家组成,每个token激活8个专家,并确保每个token最多被发送到4个节点。此外,DeepSeek V3引入了冗余专家的部署策略,以实现推理阶段的负载均衡。实验结果显示,DeepSeek V3在各项基准测试中达到SOTA。
DeepSeek V3的代码已在官方平台开源,可直接下载测试,体验地址为chat.deepseek.com,技术报告地址为https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf,抱抱脸开源地址为https://huggingface.co/deepseek-ai/DeepSeek-V3。
原文和模型
【原文链接】 阅读原文 [ 2270字 | 10分钟 ]
【原文作者】 Founder Park
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★☆


相关文章



