文章摘要
【关 键 词】 AI竞争、模型推理、数据预训练、技术保密、经济价值
中国人工智能实验室DeepSeek发布的低成本推理大模型R1性能与OpenAI的o1相当,引发对美国在AI领域领先地位的担忧。AI领域分析师Alberto Romero提出,OpenAI的GPT-5已存在,但因经济价值问题未公布。他指出,AI厂商耗尽了高质量预训练数据源,开始守护知识,不再分享成果。运营成本高昂,3亿人使用AI产品一周即可使企业资金链断裂。网友推测,o3可能是基于完整GPT-5的推理模型,o1基于4o或GPT-5的提炼,o3使用费更高,证明运行完整GPT-5的高推理成本合理。也有网友认为,AI公司一旦拥有类似AGI的东西,就不会发布,以统治市场。
OpenAI核心人才去年频繁出走,高层变动频繁。前安全研究员丹尼尔·科科塔洛透露,OpenAI在开发AGI方面接近成功,但似乎未准备好应对挑战。首席科学家Ilya Sutskever和RLHF发明者之一Jan Leike在GPT-4o发布第二天离开OpenAI,CTO Mira Murati也带着研究主管Bob McGrew和研究副总裁Barret Zoph离开。
Romero的文章《This Rumor About GPT-5 Changes Everything》引发热议,提出GPT-5已存在,但只在内部运行,因为投资回报远高于发布给用户。他澄清这是个人猜测,所有证据公开透明,没有内部消息。他提出,如果GPT-5存在且正在塑造世界,该如何?他整理资料,尝试证明这个猜想的合理性。
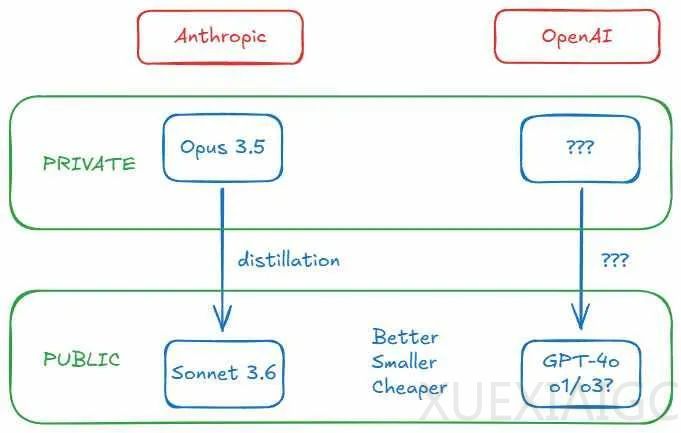
Anthropic的Claude Opus 3.5未能如约亮相,而是推出了Sonnet 3.5的更新版本Sonnet 3.6。Opus 3.5去哪了?Anthropic似乎没有能与GPT-4o正面抗衡的选手。Romero提出,顶尖AI厂商开始守护强模型“金矿”,使用昂贵模型生成数据,提升其他模型性能,称为蒸馏。Anthropic使用Opus 3.5生成合成数据,改进Sonnet 3.6性能。OpenAI和Anthropic的最新模型比上一代更强、更小、更便宜,可能通过蒸馏实现。
Romero提出,OpenAI可能面临训练GPT-5的硬件要求障碍。GPT-5可能性能更强、体量更大,训练成本和推理成本更高。为3亿用户提供庞大推理服务的可能性不大。AI厂商需证明数万亿参数模型能创造相应经济价值,否则不公布。OpenAI和Anthropic可能将大型“教师”模型保留在内部,蒸馏出较小“学生”模型推向市场,如Sonnet 3.6和GPT-4o/o1。
Romero提出,OpenAI可能在内部运行GPT-5,不打算发布,最强成果是ChatGPT o系列和Claude Sonnet系列模型。OpenAI对Scaling Law的探索深入,GPT-5需突破的预期门槛越来越高。训练新基础模型对OpenAI内部有意义,不一定作为产品推出。基础模型可能在后台运行,帮助其他模型实现壮举。即使GPT-5发布,影响也不大,OpenAI和Anthropic已意识到领先地位,不必担心偶尔露出的高招对其地位构成威胁。OpenAI可能继续推出o4和o5,找到新的生态闭环。每一代新模型的推出,都在为他们的技术火箭添加新的喷射引擎。事实是否如此,让时间给我们答案。
原文和模型
【原文链接】 阅读原文 [ 5972字 | 24分钟 ]
【原文作者】 AI前线
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章



