文章摘要
【关 键 词】 人工智能、模型成本、技术评价、公司背景、硬件资源
谷歌DeepMind首席执行官Demis Hassabis近期对DeepSeek模型的技术价值与成本争议发表评论,引发行业关注。Hassabis承认DeepSeek是”来自中国的最好作品”,其工程实现能力”在地缘政治层面改变了一切”,但强调该模型“未展示任何新的科学进步”,核心技术均基于谷歌与DeepMind已有的研究成果。他同时指出,谷歌Gemini 2.0 Flash模型在效率上优于DeepSeek,并质疑其宣称的低成本训练存在误导性。
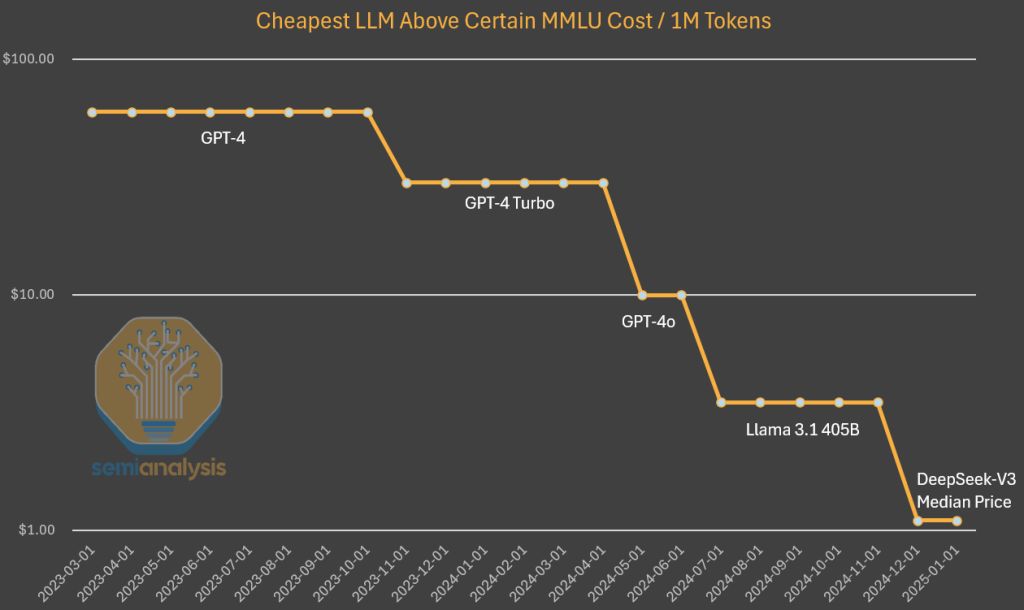
关于557.6万美元训练成本的争议,独立研究机构SemiAnalysis指出该数字仅涵盖预训练阶段的直接GPU租赁费用,实际总投入可能超过5亿美元。这包括硬件研发、架构设计、数据清洗及实验探索等隐性成本。DeepSeek在论文中明确说明,其成本计算基于算法与硬件的协同优化,2048块H800 GPU集群在两个月内完成预训练,总GPU小时数278.8万。但SemiAnalysis以Claude 3.5 Sonnet数千万美元级训练成本为例,强调模型开发的全周期投入远超表面数据。
算法进步带来的成本下降趋势成为讨论焦点。GPT-3级别模型的推理成本已降至初始值的1/1200,而SemiAnalysis测算算法效率每年提升4倍,预计到2024年底DeepSeek服务成本可能再降80%。该机构认为,中国团队首次实现这种成本能力组合才是引发关注的核心,而非技术突破本身。
DeepSeek背后依托幻方量化的雄厚资源支撑。这家管理规模超600亿元的对冲基金在2021年已部署1万张A100 GPU,当前拥有约2万张H800/H100及大量H20芯片,总硬件投资估算达16亿美元。其分散式GPU集群虽带来运营挑战,但为模型研发提供充足算力保障。人力配置方面,团队规模约150人,顶尖人才年薪可达130万美元,远超行业平均水平。招聘信息显示,多数岗位提供14薪制,应届生日薪达500-1000元,实习生亦可自由使用万级GPU资源。
运营成本结构分析显示,DeepSeek年度服务器运营支出约9.44亿美元,且在北京核心商务区设有办公场地。尽管工商信息显示其社保缴纳人数有限,但通过与母公司幻方量化的资源协同,团队持续快速扩张。当前,DeepSeek在算法优化与硬件利用方面展现的工程能力,正推动行业重新评估中国AI实验室的技术突破路径与商业化潜力。
原文和模型
【原文链接】 阅读原文 [ 2580字 | 11分钟 ]
【原文作者】 AI前线
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★★


相关文章




