DeepMind终结大模型幻觉?标注事实比人类靠谱、还便宜20倍,全开源
文章摘要
【关 键 词】 DeepMind、大语言模型、事实性评估、SAFE、LongFact
DeepMind最近提交的一篇论文《Long-form factuality in large language models》引发了热议。
该论文提出了一种新的方法,可以对大语言模型的长篇事实性进行评估和基准测试,这种方法被称为搜索增强事实评估器(Search-Augmented Factuality Evaluator,SAFE)。
这项研究的目标是解决大语言模型在响应开放式主题的事实寻求提示时,可能会生成包含事实错误的内容的问题。
研究者首先使用GPT-4生成了一个名为LongFact的提示集,该集合包含38个主题和数千个问题。
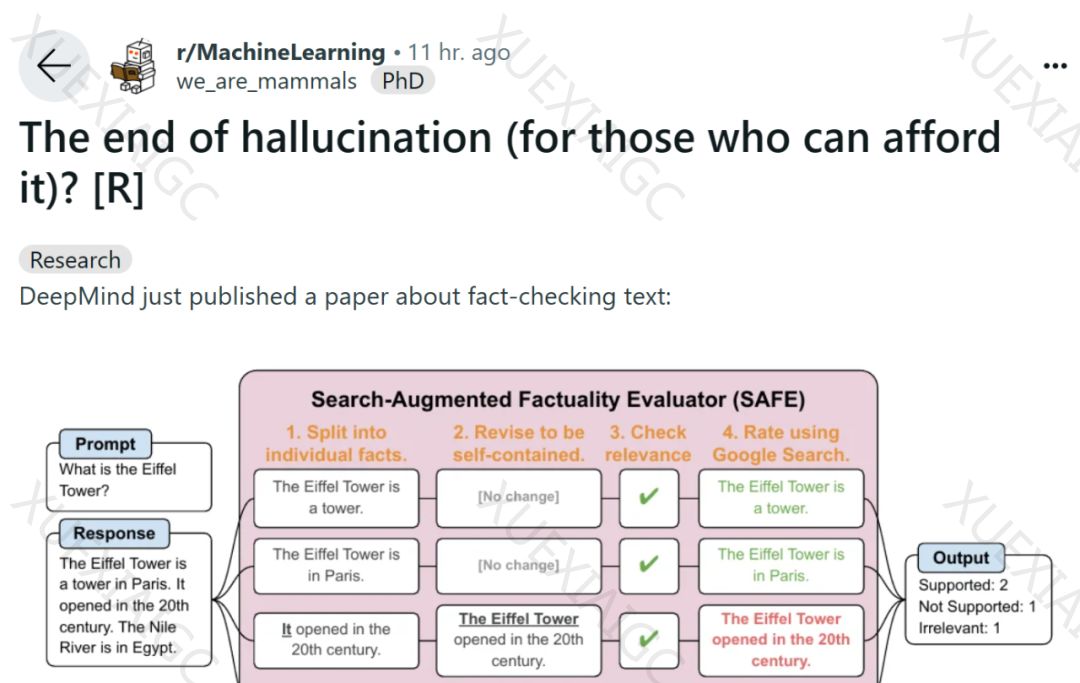
然后,他们使用SAFE将LLM智能体用作长篇事实性的自动评估器。
SAFE的工作原理是利用LLM将长篇响应分解为一组单独的事实,并使用多步推理过程来评估每个事实的准确性。
这个多步推理过程包括将搜索查询发送到Google搜索并确定搜索结果是否支持某个事实。
此外,研究者还提出了一种新的聚合指标,即将F1分数扩展为长篇事实性的聚合指标。
他们平衡了响应中支持的事实的百分比(精度)和所提供事实相对于代表用户首选响应长度的超参数的百分比(召回率)。
实验结果表明,LLM智能体可以实现超越人类的评级性能。
在一组约16k个单独的事实上,SAFE在72%的情况下与人类注释者一致,并且在100个分歧案例的随机子集上,SAFE的赢率为76%。
同时,SAFE的成本比人类注释者便宜20倍以上。
研究者还使用LongFact对四个大模型系列(Gemini、GPT、Claude 和 PaLM-2)的13种流行的语言模型进行了基准测试,结果发现较大的语言模型通常可以实现更好的长篇事实性。
这项研究的结果表明,对于负担得起的人来说,大语言模型的幻觉不再是问题。
这也可能意味着人类标注者的工作可能会受到影响,因为机器可以以更低的成本提供更高的准确性。
然而,这也为未来的研究提供了新的工具和方法,可以更准确地评估和改进大语言模型的性能。
原文和模型
【原文链接】 阅读原文 [ 1867字 | 8分钟 ]
【原文作者】 机器之心
【摘要模型】 gpt-4-32k
【摘要评分】 ★★★★☆


相关文章


