作者信息
【原文作者】 李孟聊AI
【作者简介】 独立开源软件开发者,SolidUI作者。老程序员,老扑街作者,依然奋战在开源一线,依然热爱写文章。https://www.zhihu.com/people/dlimeng
【微 信 号】 apache_linkis
文章摘要
【关 键 词】 CLIP、多模态、对比学习、数据来源、开源项目
感谢您提供的文章总结。下面是对文章中所有重要的词语或语句进行加粗处理:
介绍
OpenAI 在 2021 年提出了 CLIP(Contrastive Language–Image Pretraining)算法,这是一个先进的机器学习模型,旨在理解和解释图像和文本之间的关系。CLIP 的核心思想是通过大规模的图像和文本对进行训练,学习图像内容与自然语言描述之间的对应关系。这种方法使得模型能够在没有特定任务训练的情况下,对广泛的视觉概念进行理解和分类。
历史
多模态学习涉及同时使用和分析多种不同类型的数据,而 CLIP 是在这一领域的重要发展。在 CLIP 之前,大多数人工智能系统主要关注单一模态的处理,但随着技术的发展,研究人员开始探索如何结合不同模态的数据来提高人工智能系统的理解和分析能力。CLIP 的推出激发了更多关于多模态学习的研究和开发,推动了人工智能向更复杂、更全面的理解和处理不同类型数据的方向发展。
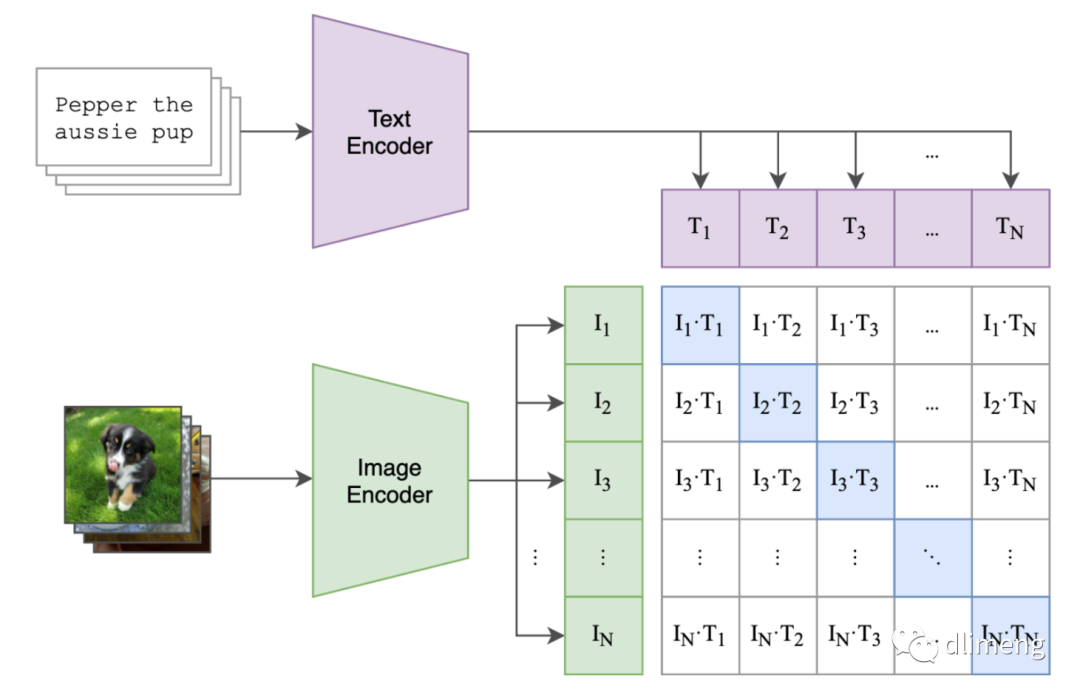
CLIP 解决方案
OpenAI CLIP 模型是针对图像和文本之间的关系设计的,与 GPT 模型的设计目的和应用场景不同。CLIP 使用对比学习方法同时处理和理解图像和文本信息,而 GPT 主要处理文本数据。CLIP 的成功展示了多模态学习在实际应用中的潜力,包括图像分类、内容创建、自动标注等领域。
数据来源
CLIP 模型是在一个包含约4亿个图像-文本对的数据集上训练的,这个数据集的规模使得模型能够学习并理解广泛的视觉概念和自然语言描述。大规模的数据集对于训练如 CLIP 这样的多模态模型来说至关重要,因为它们提供了足够的样本来捕捉和理解图像内容和相关文本之间复杂的关系。
监督信号
CLIP 模型实现监督信息的方式是通过对比学习,这是一种自监督学习方法,不需要传统的标注数据集。CLIP 通过图像和文本编码器生成特征向量,并使用对比损失函数来训练模型,使其能够在没有显式标注的情况下学习图像内容与文本描述之间的语义关系。
扩散模型与CLIP
在结合 CLIP 架构时,可以采取一系列步骤,包括使用 CLIP 的文本编码器和图像编码器处理输入,将来自 CLIP 的语义表示作为条件输入,以及在 U-Net 的每个层次中通过交叉注意模块将文本的条件表示与图像的特征结合起来。
CLIP 开源项目
OpenAI 开源了 CLIP 模型的权重,后来的学者开始复现 OpenAI 的工作,包括 OpenCLIP、ChineseCLIP 和 EVA-CLIP 等项目。
原文信息
【原文链接】 阅读原文
【原文字数】 3176
【阅读时长】 11分钟

相关文章





