文章摘要
【关 键 词】 开源AI、定义模糊、大公司、模型评估、透明度
在AI时代,开源的定义变得模糊不清。传统软件中的开源概念,如Linux和Windows的对比,已经不再适用于AI模型。Open Source Initiative(OSI)指出,传统的开源代码和使用许可的观点不足以保证AI组件的使用、研究、共享和修改的自由。OSI提出,开源AI系统应提供训练数据的详细信息、用于训练和运行的源代码以及模型参数。
荷兰的两位学者在ACM FAccT会议上发表了一篇论文,讨论了AI行业中开源定义的模糊性,并创建了一个排行榜来识别最开放和最不开放的模型。论文指出,一些大公司声称其模型开源,但实际上披露的信息非常有限,这种行为被称为open-washing。Mozilla基金会的高级研究员Abeba Birhane称赞这项研究揭示了当前开源讨论中的大量炒作和虚假信息。
给模型贴上开源标签不仅对社区和开发者有吸引力,还能在法律和商业层面带来回报。欧盟的人工智能法案对开源模型有一定的豁免,降低了透明度要求。在这种背景下,许多大公司通过博客文章发布模型,避免了科研论文的详细审查和同行评审,从而不必披露不想公开的数据。
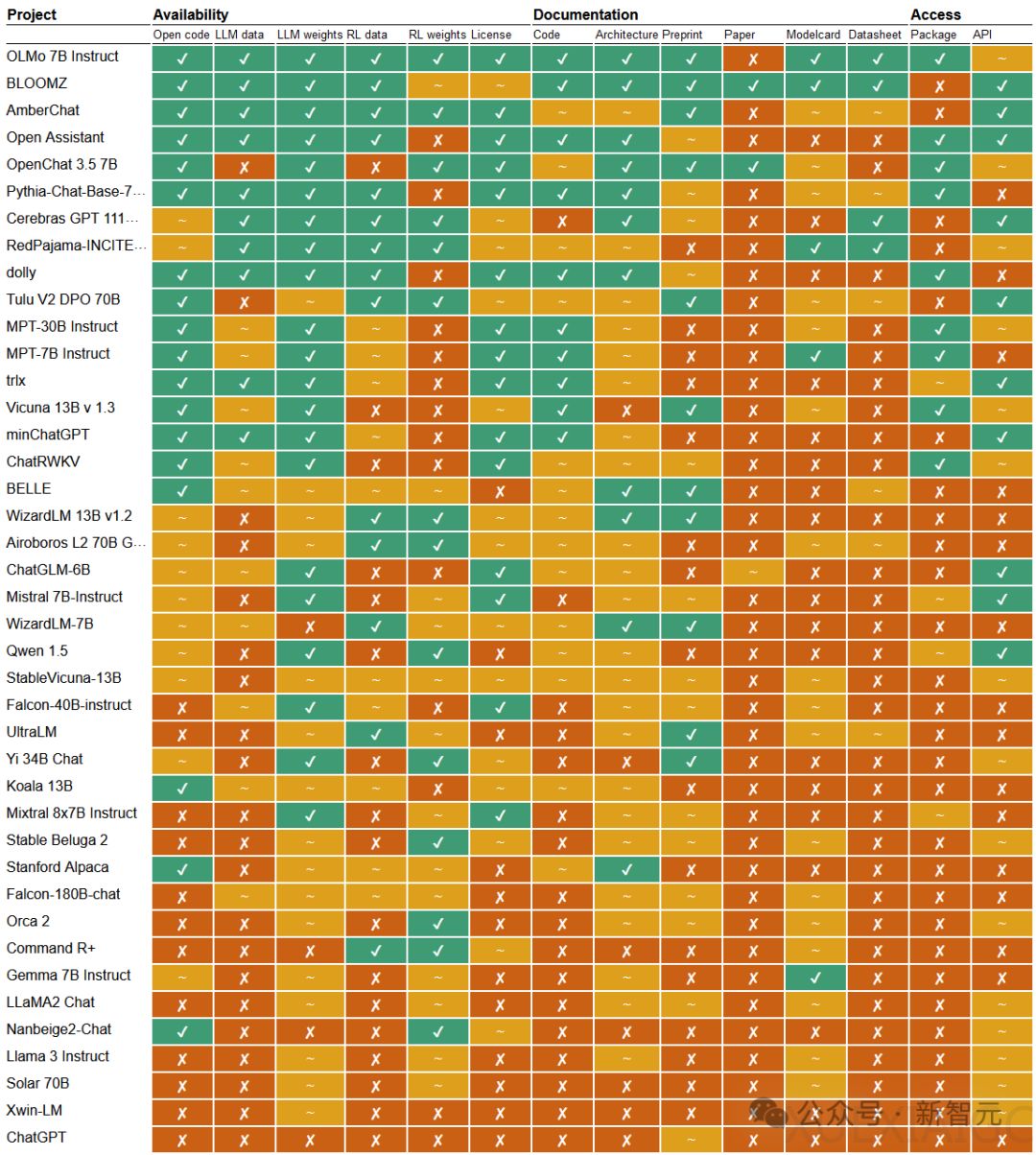
论文提出,鉴于生成式AI系统的复杂性,最有效的方法是将开放性视为一个复合且分级的概念。作者对46个声称开源或开放的大模型和众多小型模型进行了多维度评估,在14个参数上进行了分类:开放、部分开放和封闭。这些参数涵盖了可用性、文档和访问与许可三个方面。
评估结果显示,较小的团队通过高标准的公开和透明来弥补模型在规模和性能方面的不足。Allen AI发布的OLMo系列和BigScience的Bloom被认为是开源的典范,提供了训练数据、代码、文档和整个模型的pipeline。相比之下,三分之一的系统只提供模型权重,其他方面几乎不公开任何细节。科技巨头如ChatGPT、Cohere、谷歌和微软在开放性方面表现不佳,尤其是在训练数据的透明性和严谨的科研论文发布方面。
除了文本模型,论文还对文生图模型进行了评估。OpenAI的DALL-E排名倒数第一,而Stable Diffusion表现尤为突出,几乎公开了所有信息。论文没有给出具体评分,而是提供了概览图,强调评分可以被操纵,不同的派生方法和权重会得到不同的结果。
为了实现安全的AGI,需要不盲目的开放。论文呼吁在分析开放程度时,使用滑动尺度取代简单粗暴的分类方法,以更实际且有用的方式评估模型的开放性。
原文和模型
【原文链接】 阅读原文 [ 2436字 | 10分钟 ]
【原文作者】 新智元
【摘要模型】 gpt-4o
【摘要评分】 ★★★★★


相关文章




