7B扩散LLM,居然能跟671B的DeepSeek V3掰手腕,扩散vs自回归,谁才是未来?
文章摘要
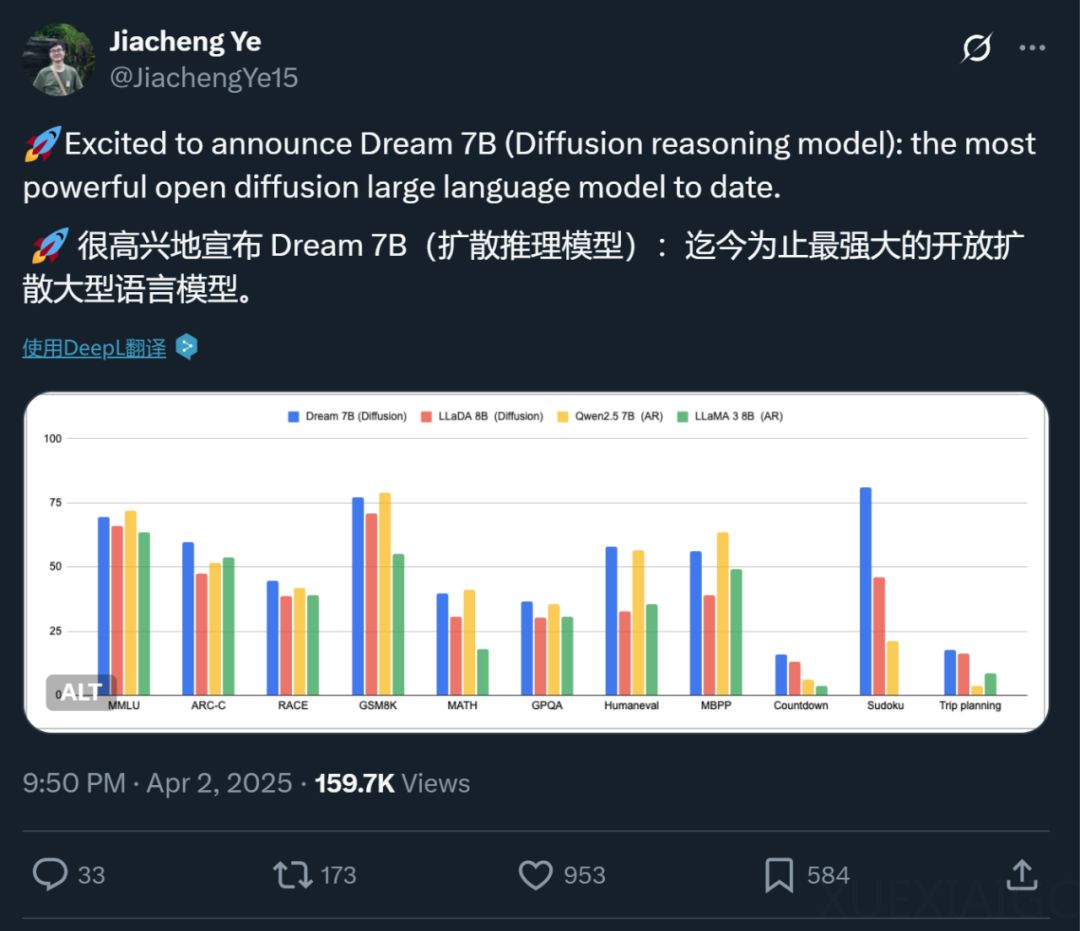
香港大学与华为诺亚方舟实验室合作开发的扩散推理模型 Dream 7B,在开源扩散语言模型领域取得了新的突破,成为当前性能最佳的模型。该模型在通用能力、数学推理和编程任务上,展现了与顶尖自回归模型(如 Qwen2.5 7B 和 LLaMA3 8B)相媲美的表现,甚至在部分任务中超越了最新的 Deepseek V3 671B。Dream 7B 的独特优势在于其规划能力和推理灵活性,进一步验证了扩散模型在自然语言处理领域的潜力。
扩散模型与自回归模型的对比是研究的核心。自回归模型(如 GPT-4)通过从左到右逐个生成 token,虽然表现卓越,但在复杂推理、长期规划和上下文连贯性方面存在局限。扩散模型则从完全噪声状态起步,通过同步优化整个序列,提供了双向上下文建模、灵活可控生成以及高效采样等优势。这种架构差异使得扩散模型在处理多重约束任务和实现特定目标时更为有效。
Dream 7B 的训练过程结合了掩码扩散范式和自回归模型的初始化策略,显著提升了训练效率。研究团队利用 Qwen2.5 7B 的权重进行初始化,并通过上下文自适应的 token 级噪声重排机制,优化了每个 token 的学习过程。这一创新机制为模型提供了更精准的层次化指导,减少了预训练所需的 token 量和计算资源。
在规划能力测试中,Dream 7B 在 Countdown 和数独任务中表现优异,显著超越了同级别的自回归模型,甚至在某些情况下优于参数规模更大的 Deepseek V3。这表明扩散模型在处理复杂推理和规划任务时具有独特优势。此外,扩散模型的任意顺序生成能力,使其能够灵活应对多样化的用户查询,进一步增强了推理灵活性。
有监督微调是提升模型性能的关键步骤。研究团队从高质量指令-响应数据中筛选了 180 万对样本,对 Dream 7B 进行了三轮深度微调,使其在性能上与顶尖自回归模型比肩。未来,研究团队计划进一步探索为扩散语言模型量身定制的后训练优化方案,以挖掘其更大的潜力。
总体而言,Dream 7B 的成功不仅验证了扩散模型在自然语言处理领域的广阔前景,也为下一代语言模型的架构设计提供了新的思路。尽管自回归模型目前仍是主流,但扩散模型在生成文本方面的天然优势,使其成为突破现有局限的重要研究方向。
原文和模型
【原文链接】 阅读原文 [ 3153字 | 13分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3/community
【摘要评分】 ★★★★★


相关文章




