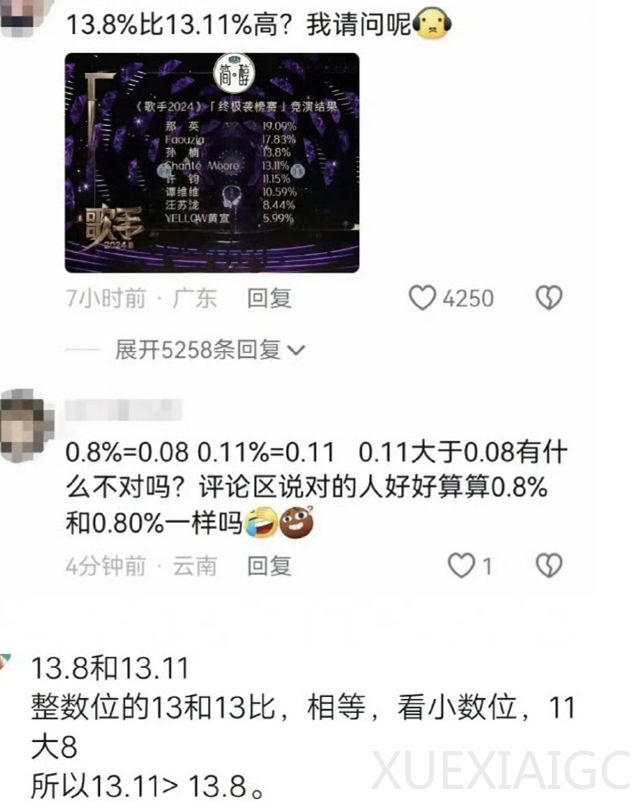
13.11 和 13.8 哪个大,不只是人类,为什么连大模型也翻车了?
文章摘要
【关 键 词】 AI错误、数字比较、提示技巧、Token理解、模型优化
在《歌手2024》第十期竞演排名公布后,社交媒体上的观众对数字大小的比较产生了疑问,而一些AI大模型在回答这类问题时也出现了错误。
例如,当被问及”9.11和9.9哪个大”时,GPT-4o等主流大模型错误地认为9.11更大。
这一现象背后的原理与大模型以token的方式来理解文字有关。
当9.11被拆分为“9”、“小数点”和“11”三部分时,模型错误地认为11比9大。
然而,当明确指出这是一个双精度浮点数时,AI就能正确处理这个问题。
为了引导大模型正确理解问题,人们开始尝试不同的提问方法。
Zero-shot CoT思维链,即“一步一步地想”,能够引导大模型正确回答问题。
总的来说,大模型在处理数字大小比较问题时容易出错,这与它们以token方式理解文字有关。
通过改变提问方式或明确指出问题类型,可以引导大模型正确处理这类问题。
同时,研究者们也在不断探索更有效的提示词技巧,以提高大模型的准确性。
原文和模型
【原文链接】 阅读原文 [ 1480字 | 6分钟 ]
【原文作者】 Founder Park
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...



