文章摘要
【关 键 词】 模型可靠性、语言模型、难度不一致、任务回避、人类监督
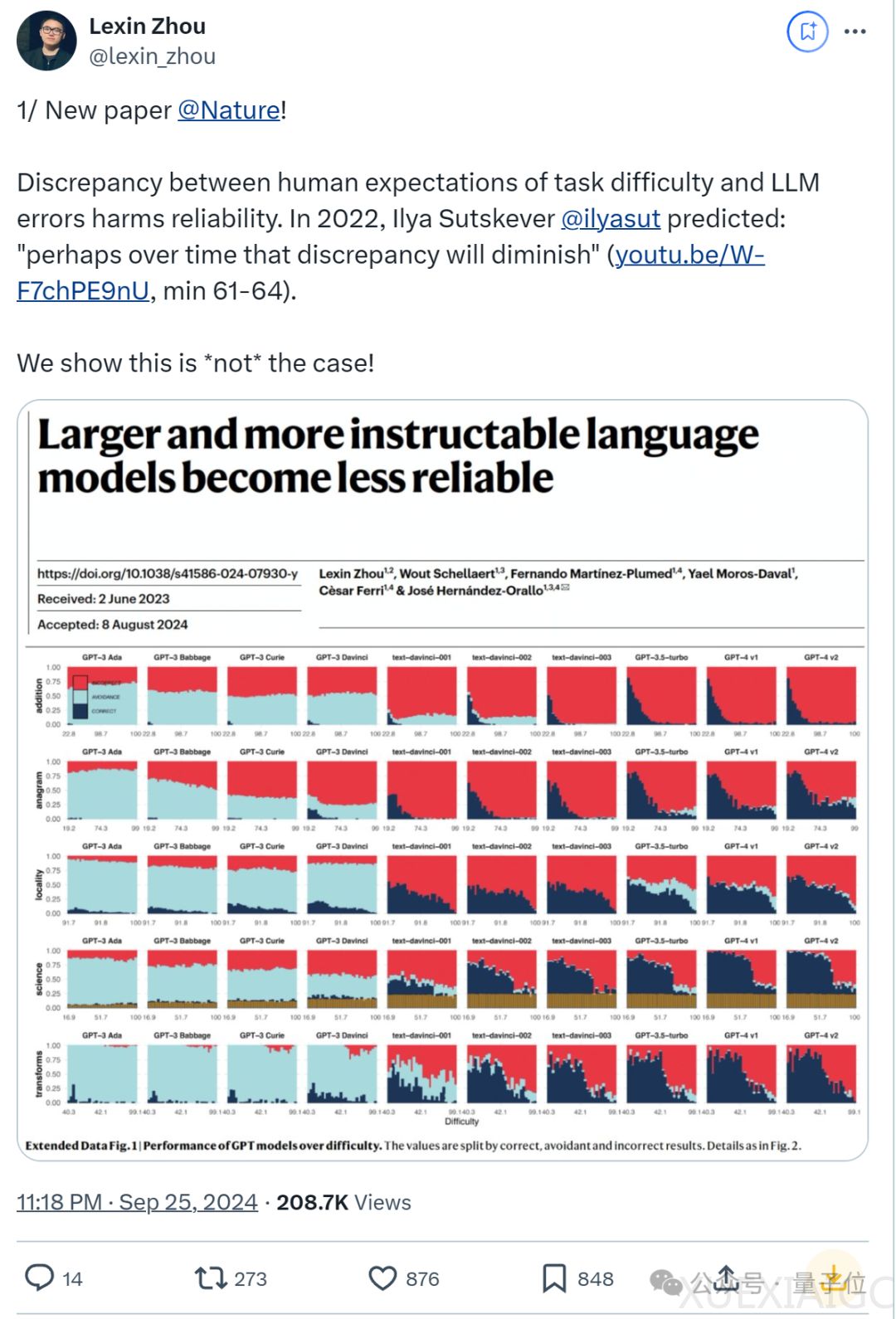
这篇论文探讨了大型语言模型(LLMs)的可靠性问题,发现随着模型规模的增大,其在遵循指令方面的表现反而变得不可靠。研究指出,即使是最新的模型,如GPT-4,在回答的可靠性上也不如GPT-3。这一发现与人类对难度的预期不符,LLMs在用户预料之外的地方既成功又失败,这在高风险领域尤其令人担忧。
研究分析了影响LLMs可靠性的三个关键方面:难度不一致、任务回避和对提示语表述的敏感性。结果显示,随着任务难度的增加,所有模型的正确性都会下降,但这些模型在简单任务上的表现并没有明显改进。此外,最新的LLMs在错误或胡说八道的答案上有所增加,而不是谨慎地避开超出它们能力范围的任务。这表明,人类用户难以发现LLMs的安全操作空间。
论文还发现,即使一些可靠性指标有所改善,模型仍然对同一问题的微小表述变化敏感。而且,人类监督也无法缓解模型的不可靠性。在用户认为困难的操作区域中,他们经常将错误的输出视为正确。
研究涉及的模型包括GPT、LLaMA和BLOOM系列,以及OpenAI的o1模型、Antropic的Claude-3.5-Sonnet和Meta的LLaMA-3.1-405B。作者提出了一些可能的原因和解决方案,例如在模型训练和微调中使用人类难度预期,或者利用任务难度和模型自信度来教会模型规避超出自身能力范围的难题。
论文的第一作者是Lexin Zhou(周乐鑫),他刚从剑桥大学计算机科学硕士毕业,研究兴趣为大语言模型评测。他曾在OpenAI和Meta参与红队测试,并强调在高风险领域,依赖人类监督是一种危险,需要进行根本性的转变。
论文还开源了测试基准ReliabilityBench,这是一个包含五个领域的数据集,用于验证其他模型的可靠性问题。
原文和模型
【原文链接】 阅读原文 [ 2099字 | 9分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章


