谁才是最强的?清华给海内外知名大模型做了场综合能力评测
文章摘要
【关 键 词】 AI评测、模型比较、语义理解、智能体、安全评测
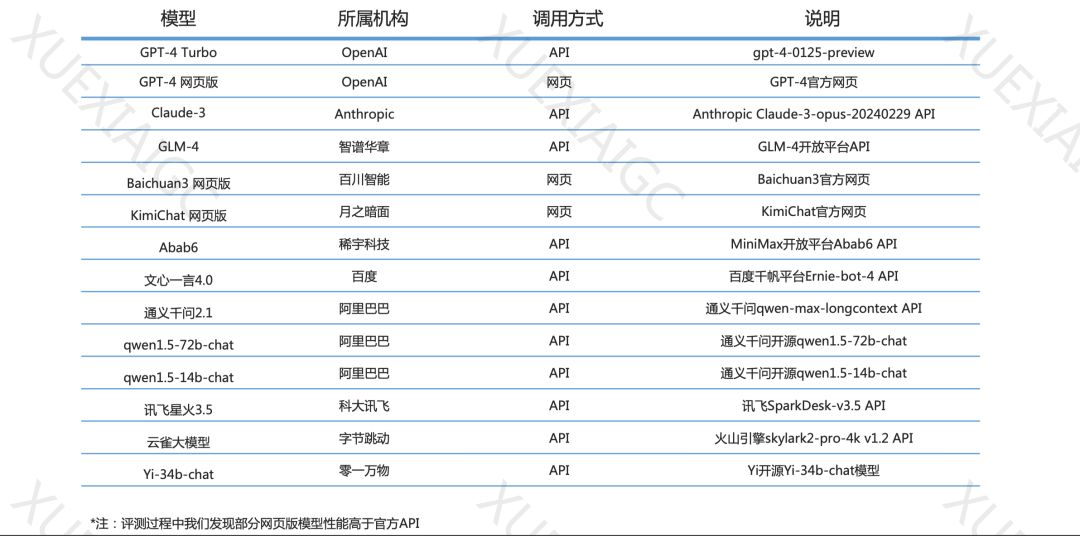
在2023年的“百模大战”中,众多实践者推出了各类模型,包括原创和针对开源模型的微调模型,以及通用和行业特定的模型。为了合理评价这些模型的能力,清华大学基础模型研究中心联合中关村实验室研制了SuperBench大模型综合能力评测框架。2024年3月发布的《SuperBench大模型综合能力评测报告》对14个具有代表性的模型进行了测试,包括闭源模型的API和网页调用模式。
报告的主要结论包括:GPT-4系列和Claude-3等国外模型在多个能力上处于领先地位,而国内头部大模型GLM-4和文心一言4.0与国际一流模型水平接近,差距逐渐缩小。在语义理解和智能体两项能力评测中,Claude-3获得榜首。国内大模型在代码编写和智能体能力上与国际一流模型有较大差距,但仍需努力。
大模型能力评测经历了五个阶段:2018-2021年的语义评测阶段,2021-2023年的代码评测阶段,2022-2023年的对齐评测阶段,2023-2024年的智能体评测阶段,以及2023年至今的安全评测阶段。SuperBench评测体系包含语义、代码、对齐、智能体和安全五个评测大类,共28个子类。
在语义评测中,使用ExtremeGLUE高难度集合,Claude-3得分最高,国内模型GLM-4和文心一言4.0表现亮眼。在代码评测中,GPT-4系列和Claude-3在代码通过率上领先,但所有模型的一次通过率仅约50%。对齐评测使用AlignBench,GPT-4网页版和文心一言4.0紧随其后。智能体评测使用AgentBench,Claude-3和GPT-4系列模型表现突出,国内模型整体落后。安全评测使用SafetyBench,文心一言4.0在安全能力评测中得分最高。
总体来看,国内外大模型在多个能力上存在差距,国内模型在部分领域表现亮眼,但仍需在代码编写和智能体能力上加强。安全评测成为未来AI可持续发展的关键问题。
原文和模型
【原文链接】 阅读原文 [ 5263字 | 22分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




