阿里发布Qwen2.5-Turbo,上下文长度突破100万
文章摘要
【关 键 词】 Qwen2.5-Turbo、超长上下文、推理速度、稀疏注意力、性能提升
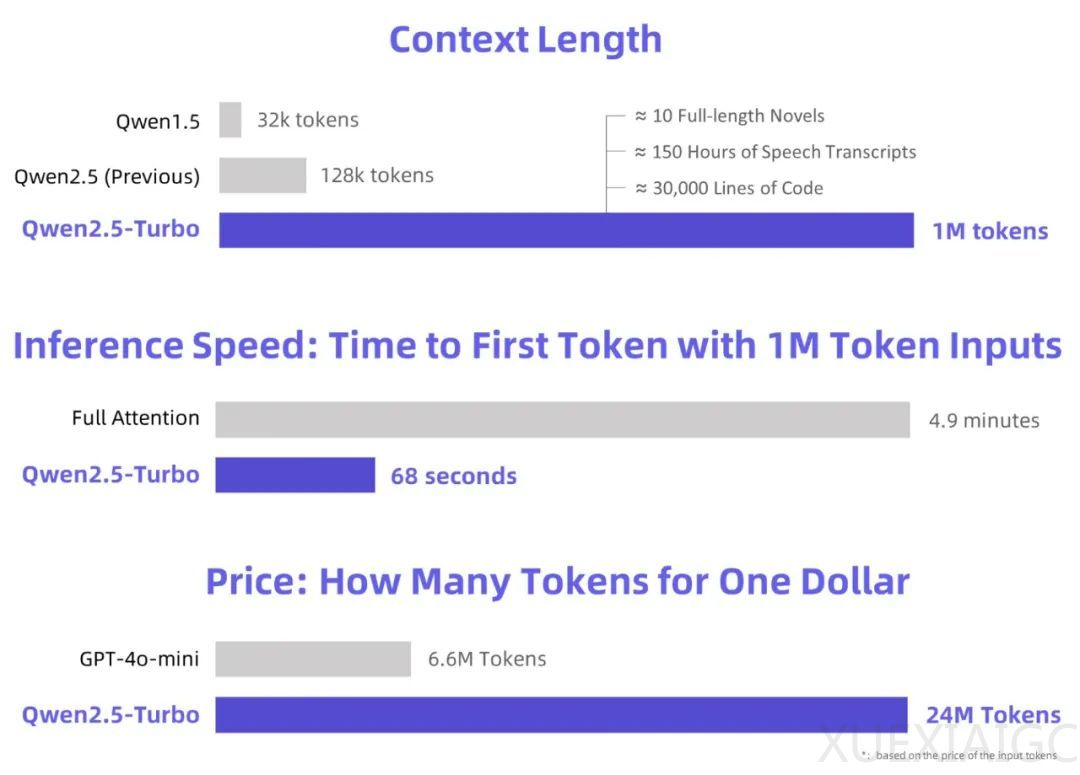
阿里巴巴通义大模型团队近日发布了Qwen2.5-Turbo,这是其最新语言模型Qwen2.5的升级版。新模型在多个方面进行了显著提升,尤其是在处理超长上下文的能力上,将上下文长度从128K扩展至1M Token,相当于约100万个英文单词或150万个汉字。在推理速度方面,Qwen2.5-Turbo通过采用稀疏注意力机制,将处理1M Token上下文时的首个Token时间从4.9分钟缩短至68秒,速度提升了4.3倍。此外,Qwen2.5-Turbo的价格更为低廉,每百万Token的处理成本仅为0.3元,在相同费用情况下,可以处理的Token量是GPT-4o-mini的3.6倍。
Qwen2.5-Turbo在长上下文的高效处理方面设立了新标杆,并在各种应用场景中保持卓越性能。它完全兼容标准Qwen API及OpenAI API,支持1M Token的调用。在模型性能方面,Qwen2.5-Turbo在长短文本任务上展现了明显进步。在1M-token Passkey Retrieval任务中,准确率达到100%。在长文本理解方面,Qwen2.5-Turbo在多个数据集上持续领先,展现了其在长文本理解上的强大能力。同时,在短文本处理任务中,Qwen2.5-Turbo依然表现强劲,领先其他竞争对手,并与GPT-4o-mini及Qwen2.5-14B-Instruct的短文本性能持平,同时支持的上下文长度是它们的8倍。
Qwen2.5-Turbo通过稀疏注意力机制实现了推理速度的明显提升,对于1M-token输入,稀疏注意力将计算量减少约87.5%,在不同硬件环境下实现了3.2到4.3倍的速度提升。尽管Qwen2.5-Turbo在1M-token上下文支持上实现了技术突破,但仍面临长序列任务性能不稳定和推理成本较高的挑战。阿里巴巴团队表示,将继续优化长序列任务的人类偏好对齐、提高推理效率以及探索更强大的长上下文模型来应对这些挑战。
原文和模型
【原文链接】 阅读原文 [ 952字 | 4分钟 ]
【原文作者】 AI大模型实验室
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★☆☆☆☆


相关文章




