文章摘要
【关 键 词】 长文本处理、无限注意力、技术创新、上下文模型、AI应用
近期,长文本处理技术在人工智能领域取得了显著进展。谷歌推出了大模型Gemini 1.5,能够处理百万token的长文本。紧随其后,中国推出了Kimi智能助手,支持200万字的超长无损上下文。这些进展引起了行业内大厂的关注,如阿里巴巴、360公司和百度等,纷纷推出了自己的长文本处理能力。
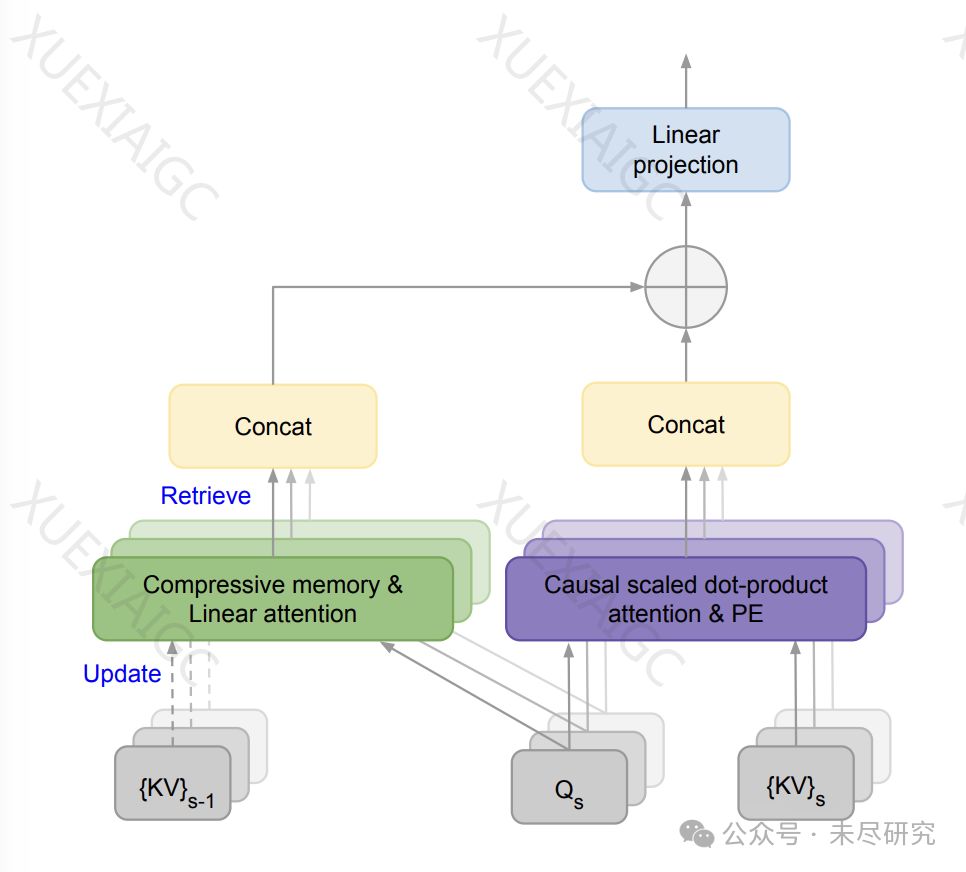
谷歌发表了一篇论文,介绍了其在长文本处理方面的技术创新。通过对Transformer模型的常规注意力机制进行改进,谷歌发明了一种名为无限注意力(Infini-attention)的新技术。这种技术能够在有限的内存和计算量下高效处理无限长的输入序列,将压缩内存集成到标准的注意力机制中,并在单个Transformer块内构建了掩码局部注意力和长期线性注意力机制。
无限注意力技术的核心在于压缩记忆的引入,它能够在特定的上下文中提高计算效率。与传统注意力机制不同,改进后的注意力机制将旧的KV状态存储在压缩内存中,用于长期记忆中的巩固和检索。在处理后续序列时,注意力查询可以从压缩内存中检索值,Infini attention会聚合从长期记忆检索的值和局部注意力上下文。
这一技术的应用使得基于Transformer的模型能够在有限的内存占用下处理更长的上下文。实验结果表明,具有Infini-attention的10亿参数大模型可以在内存不变的情况下自然扩展到100万上下文。经过持续预训练和任务微调,具有Infini-attention的80亿参数模型在50万长度书籍摘要任务上达到了最佳性能。
长上下文模型已成为人工智能实验室研究的重要领域和竞争焦点。Anthropic的Claude 3支持最多20万token,而OpenAI的GPT-4的上下文窗口为12.8万个token,直到Gemini 1.5达到百万token。无限上下文技术的发展为定制应用程序提供了可能性,降低了进入应用程序的门槛,使开发者和组织能够快速创建工作原型,而无需巨大的工程努力。
无限上下文技术并不意味着会取代其他技术,如微调或检索增强生成(RAG)。相反,它将有助于企业和机构优化其模型管道,降低成本并提高速度和准确性。随着技术的进步,支持百万上下文模型的AI系统很快可以安装在笔记本电脑上,为人工智能领域带来更广泛的应用前景。
原文和模型
【原文链接】 阅读原文 [ 1023字 | 5分钟 ]
【原文作者】 AI工程化
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆


相关文章




