这就翻车了?Reflection 70B遭质疑基模为Llama 3,作者:重新训练
文章摘要
【关 键 词】 AI写作、开源模型、基准测试、社区质疑、重新训练
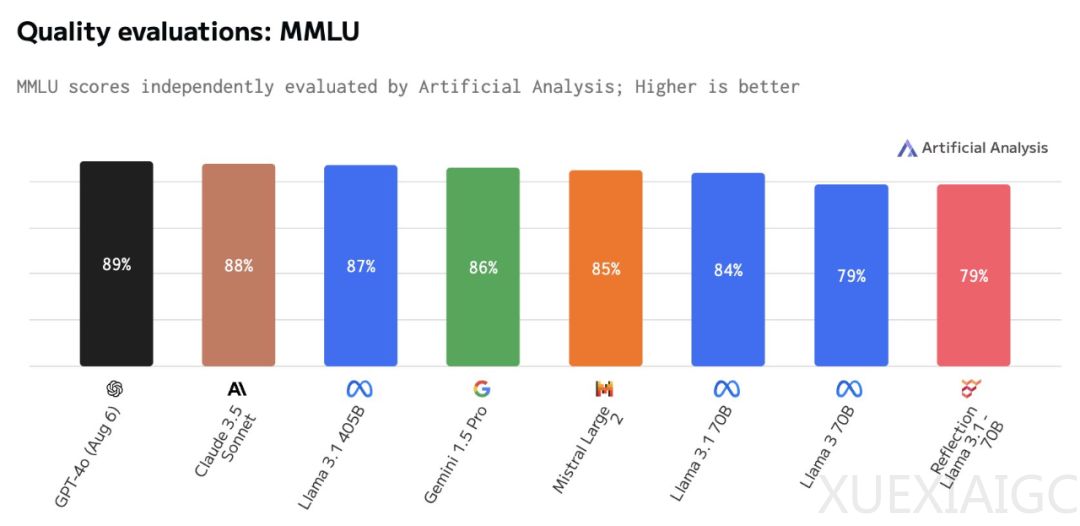
AI写作初创公司HyperWrite开发的新模型Reflection 70B在开源大模型社区引起了广泛关注。该模型基于Meta Llama 3.1 70B Instruct构建,采用原始Llama chat格式,以确保与现有工具和pipeline的兼容性。在MMLU、MATH、IFEval、GSM8K等基准测试中,Reflection 70B超越了GPT-4o,甚至击败了405B的Llama 3.1,被誉为开源大模型新王。然而,AI模型独立分析机构Artificial Analysis的独立评估测试结果显示,Reflection Llama 3.1 70B在MMLU得分上仅与Llama 3 70B相同,且明显低于Llama 3.1 70B。此外,在科学推理与知识(GPQA)和定量推理(MATH)基准测试中,Reflection 70B的表现也不如Llama 3.1 70B。
Reddit上的LocalLLaMA社区帖子比较了Reflection 70B与Llama 3.1、Llama 3权重的差异,发现Reflection模型似乎使用了经过LoRA调整的Llama 3而非Llama 3.1。这一发现引发了社区的质疑,有人怀疑Reflection 70B模型的炒作和关注可能与开发者Matt Shumer的利益相关。面对质疑,Matt Shumer澄清称Hugging Face权重出现问题,并表示已经重新上传权重,但问题仍然存在。他宣布将开始重新训练模型并上传,以消除任何可能出现的问题。
Matt Shumer还回应了其他质疑,包括对GlaiveAI的投资情况、为什么Hugging Face上的基础模型为Llama 3而非Llama 3.1,以及基准测试中有关LoRAing的问题。他解释称,自己只是GlaiveAI的一个小投资者,基础模型的问题正在解决中,而关于LoRAing的疑问,他表示将在下周与405B(或更早)一起发布数据集,届时可以查看。社区对重新训练后的Reflection 70B的表现充满期待。
原文和模型
【原文链接】 阅读原文 [ 1081字 | 5分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★☆☆☆☆


相关文章



