谷歌终于赢了OpenAI一回:实验版本Gemini 1.5 Pro超越GPT-4o
文章摘要
【关 键 词】 人工智能、Gemini 1.5 Pro、谷歌、多语言任务、实验阶段
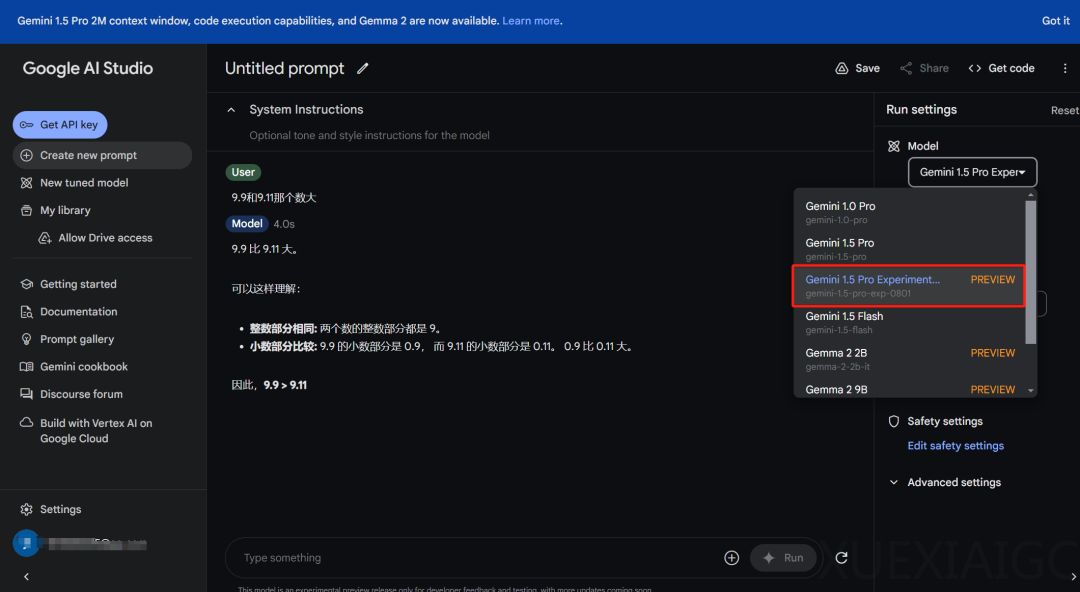
谷歌近期推出了一款名为Gemini 1.5 Pro (0801)的人工智能模型,该模型在Google AI Studio和Gemini API上供用户免费测试和反馈。在一项测试中,Gemini 1.5 Pro (0801)能够正确回答9.9和9.11哪个数大的问题,并给出理由。然而,在分析”Strawberry”单词中”r”的数量时,模型在第四步出错。
尽管存在一些瑕疵,Gemini 1.5 Pro (0801)在官方评测中表现优异,各项指标均表现出色。该模型在著名的LMSYS Chatbot Arena排行榜上以1300分的ELO分数夺得榜首,领先于OpenAI的GPT-4o (ELO: 1286)和Anthropic的Claude-3.5 Sonnet (ELO: 1271)等竞争对手。
Gemini 1.5 Pro (0801)由谷歌团队成员Simon Tokumine领导开发,被认为是谷歌迄今为止制造的最强大、最智能的Gemini模型。除了在Chatbot Arena排行榜上取得优异成绩外,该模型在多语言任务、数学、Hard Prompt和编码等领域也表现突出。特别是在中文、日语、德语和俄语等语言任务中均排名第一。
然而,在编码和Hard Prompt领域,Claude 3.5 Sonnet、GPT-4o和Llama 405B等模型仍然占据领先地位。在win-rate热图中,Gemini 1.5 Pro (0801)对阵GPT-4o的胜率为54%,对阵Claude-3.5-Sonnet的胜率为59%。此外,Gemini 1.5 Pro (0801)在Vision排行榜上也排名第一。
网友们对谷歌这次突然开放测试最强模型表示惊讶,认为这给OpenAI带来了压力。尽管Gemini 1.5 Pro (0801)取得了很高的成绩,但它仍处于实验阶段,可能在广泛使用前会进行进一步的修改。
一些网友对Gemini 1.5 Pro (0801)的内容提取能力、代码生成能力和推理能力进行了测试。测试结果显示,该模型在图像信息提取、PDF文档内容提取和代码生成方面表现出色。例如,它可以将发票图像的详细信息以JSON格式编写出来,提取经典论文《Attention Is All You Need》的章节目录,并生成帮助学习大型语言模型知识的Python游戏。
然而,在推理能力方面,Gemini 1.5 Pro (0801)在回答”吹蜡烛”问题时出现了错误。尽管如此,该模型在视觉能力方面接近GPT-4o,在代码生成和PDF理解、推理能力方面接近Claude 3.5 Sonnet,表现出值得期待的潜力。
总的来说,Gemini 1.5 Pro (0801)作为一款实验性的人工智能模型,在多个领域展现出了强大的能力,尤其是在多语言任务和内容提取方面。虽然在某些方面仍有改进空间,但其表现已经足够引人注目,预示着人工智能领域可能迎来新的竞争格局。
原文和模型
【原文链接】 阅读原文 [ 887字 | 4分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆


相关文章




