文章摘要
【关 键 词】 大模型、合成数据、训练数据、数学推理、强化学习
随着大模型如ChatGPT的快速发展,对高质量训练数据的需求呈指数级增长,预计最快将在2026年耗尽现有的300万亿tokens的公开数据集。为了解决这一问题,合成数据被视为最有效的替代方案。卡内基梅隆大学、谷歌DeepMind和MultiOn的研究人员联合发布了一篇论文,探讨了合成数据在训练大模型中的价值。研究提出了正面和负面两种数据类型,正面数据由高性能大模型如GPT-4生成,提供了正确的示例,帮助模型学习解决类似问题。然而,仅依赖正面数据存在局限性,模型可能通过模式匹配而非真正理解来学习,且随着数据量增加,模型可能依赖错误关联,导致泛化能力降低。
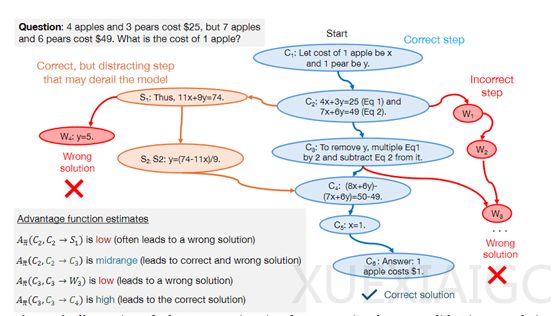
负面数据则提供了错误示例,帮助模型学习避免错误,增强逻辑推理能力。例如,国内“弱智吧”数据就属于负面数据类型。然而,负面数据的利用并不容易,错误的步骤可能包含误导性信息,加剧模型的错误学习。研究人员通过DPO(直接偏好优化)方法优化了负面数据的使用,为每个解题步骤分配优势值,反映其在正确解题路径中的相对价值。高优势值表示关键步骤,低优势值则揭示推理问题。通过强化学习,模型动态调整策略,更高效地学习和改进合成数据。
在DeepSeek-Math-7B、LLama2-7B等模型上的测试显示,经过正面和负面合成数据预训练的大模型,在数学推理任务上的性能提升了8倍。这表明,通过纠正错误并从中学习,大模型能够更有效地掌握数学逻辑和问题解决技巧。这一研究为大模型的训练提供了新的思路,强调了合成数据在提升模型性能中的重要作用。
原文和模型
【原文链接】 阅读原文 [ 935字 | 4分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-v3
【摘要评分】 ★☆☆☆☆


相关文章




