作者信息
【原文作者】 清熙
【作者简介】 清晰、客观、理性探讨大模型(LLM)、人工智能(AI)、大数据(Big Data)、物联网(IoT)、云计算(Cloud)、供应链数字化等热点科技的原理、架构、实现与应用。
【微 信 号】 qingxitech
文章摘要
【关 键 词】 视频生成、时空碎片、扩散模型、视觉语言、AI前景
OpenAI发布的Sora视频生成模型在AI领域引起了巨大轰动,被视为继ChatGPT之后又一次重要的技术突破。本文详细总结了Sora的关键技术和潜在应用,并与Google的Lumiere模型进行了比较。以下是文章的五个主要部分:
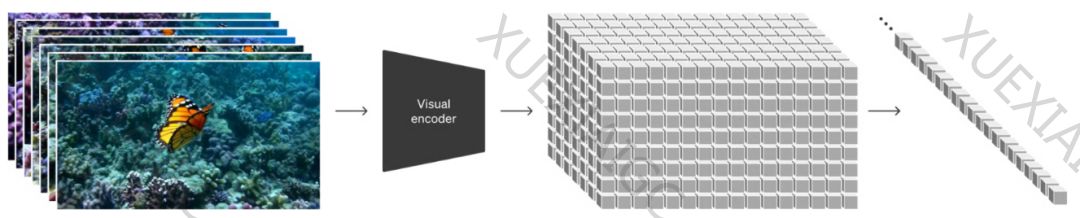
1. Spacetime Latent Patches:Sora模型采用时空潜变量碎片来构建视觉语言系统。这种方法类似于ChatGPT使用的Token Embedding,能够将视频数据压缩到低维空间并进行有效表征。时空碎片的统一语言使得Sora能够执行多种任务,如自然语言理解、图像和视频编辑等。
2. Diffusion Transformer:Sora基于扩散模型和Transformer架构,被称为Diffusion Transformer。这种模型通过连续添加高斯噪声来破坏训练数据,然后学习恢复数据。扩散模型的训练目标是学习一个去噪过程,以便生成新的数据。
3. 时空碎片的动态关联:Sora利用Diffusion Transformer在潜变量时空碎片上学习丰富的时空碎片之间的关联和演化过程。这与人类视觉观察相似,可以帮助模型捕捉到视频中的时空信息。
4. 视频学习与生成的技术原理:Sora在时空潜变量碎片上学习到了可视层面的SSM(State Space Model),从而在视频生成上展现出强大的涌现能力。OpenAI认为,随着视频模型规模的扩大,它们可以用来模拟整个物理和数字世界。
5. Sora的前景与未来:Sora和Lumiere等文生视频模型代表了从侧重空间关联到加强时间关联的转变。未来,这些模型有望辅助人类科学家发现潜在的规律,并将AI推向人工超级智能的水平。
原文信息
【原文链接】 阅读原文
【原文字数】 3896
【阅读时长】 13分钟

相关文章






Of cause, it’s my pleasure.