英伟达开源「描述一切」模型,拿下7个基准SOTA
文章摘要
【关 键 词】 图像描述、多模态、视频分析、局部细节、自然语言
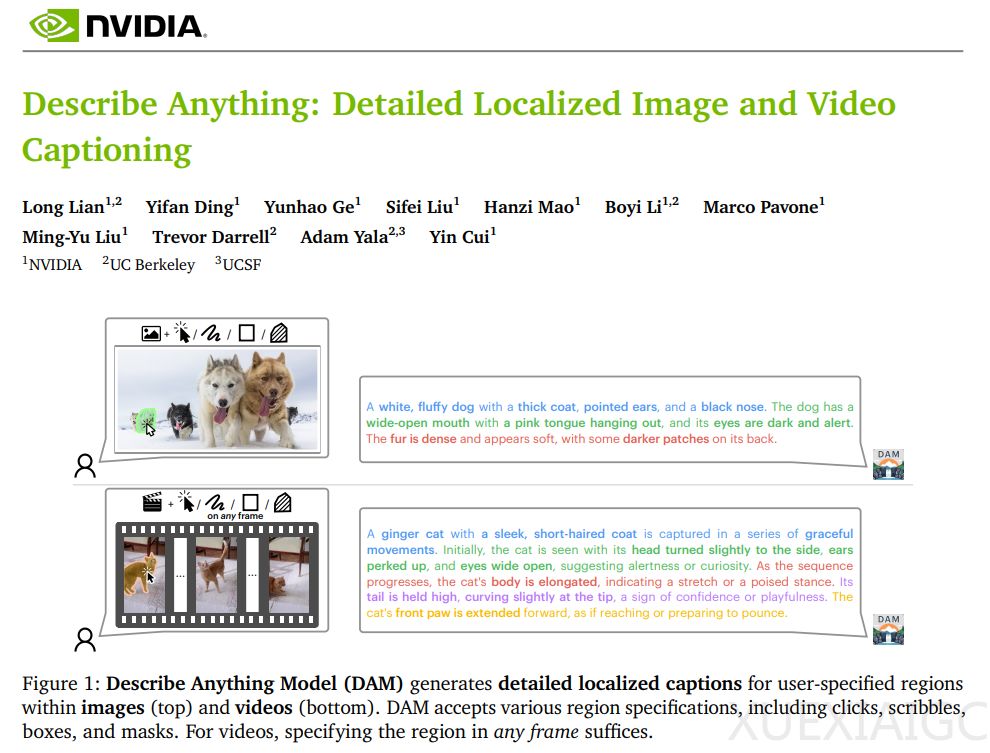
为了实现这些功能,DAM 采用了两个关键创新:焦点提示(focal prompt)和局部视觉骨干网络(localized vision backbone)。焦点提示通过提供完整图像和目标区域的放大视图,确保模型既能捕捉精细细节,又能保留全局背景。局部视觉骨干网络则通过门控交叉注意力层将局部细节与全局上下文融合,从而生成更丰富、更具上下文感知能力的描述。
由于现有数据集缺乏详细的局部化描述,研究者设计了一个两阶段流程来构建高质量训练数据。首先,他们使用 VLM 将简短类别标签扩展为丰富的描述;其次,在未标记图像上应用自训练方法,生成并优化新的描述。这种方法显著减少了对手工注释的依赖,同时提升了数据集的质量。
在实验中,DAM 在局部图像与视频描述任务中表现卓越,支持多粒度输出(包括关键词、短语及详细描述),并在多个基准测试中达到 SOTA(State of the Art)水平。例如,在 Ref-L4 基准测试中,DAM 在短语言描述指标上相对提升了 33.4%,在长语言描述指标上相对提升了 13.1%。此外,DAM 在零样本和域内设置中均超越了之前的最佳成绩,展示了其强大的泛化能力。
DAM 的推出标志着图像和视频描述技术的重大进步,为多模态理解和生成任务提供了新的可能性。其灵活性和准确性使其在学术研究和实际应用中都具有广泛潜力。
原文和模型
【原文链接】 阅读原文 [ 1968字 | 8分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...



