文章摘要
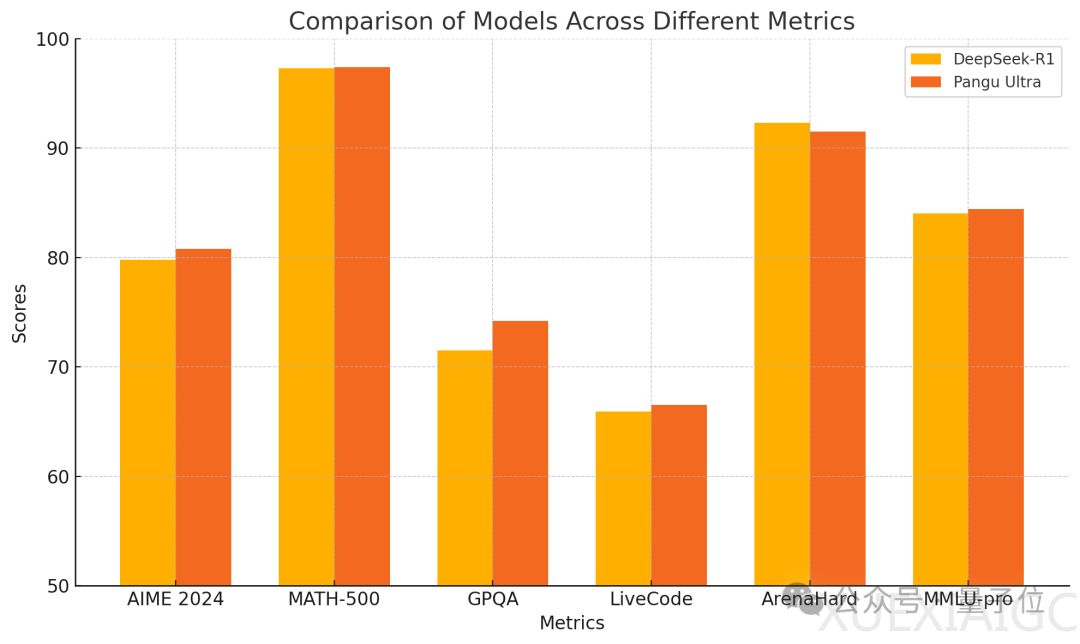
华为推出的盘古Ultra模型在推理任务中展现出了与DeepSeek-R1等大规模模型竞争的能力。尽管盘古Ultra的参数量仅为135B,但其在数学竞赛、编程等推理任务中的表现与DeepSeek-R1不相上下。这一成就得益于改进的模型架构和系统优化策略,使得盘古Ultra在训练过程中未出现损失尖峰,并且实现了52%以上的算力利用率。
盘古Ultra在预训练阶段的评测中,尤其在MMLU、TriviaQA、GSM8K等具有挑战性的数据集上,展现出了卓越的语言理解和推理能力。经过指令调优后,模型在AIME 2024、MATH-500等数学推理任务和LiveCodeBench等编程竞赛题上达到了SOTA水平,超越了包括GPT-4o、Mistral-Large 2等强大模型。
在模型架构方面,盘古Ultra采用了分组查询注意力(GQA)机制,并引入了深度缩放的Sandwich-Norm层归一化和TinyInit参数初始化策略。这些改进有效解决了深度模型训练中的不稳定性和收敛困难问题,使得训练过程更加平稳。此外,盘古Ultra还通过优化Tokenizer,构建了一个兼顾领域覆盖和编码效率的153376个token的平衡词表。
盘古Ultra的训练流程分为预训练、长上下文扩展和指令调优三个阶段。预训练阶段包括通用阶段、推理阶段和退火阶段,分别侧重于语言理解、推理能力和指令遵循能力的培养。训练过程中,研究者们采用了基于规则和模型的数据清洗方法,并设计了curriculum learning策略,让模型循序渐进地学习不同难度的样本。
在训练设施方面,盘古Ultra使用了一个由8192个昇腾AI处理器组成的大规模计算集群。集群中每个节点包含8个NPU,通过华为高速缓存一致性互联HCCS以全互联的拓扑结构连接。为了实现高效训练,研究团队采用了数据并行、张量并行、序列并行和流水线并行等多种并行方式的组合,并通过ZeRO分布式优化器和各种通信计算优化技术,最小化了通信开销,提升了计算效率。
综合来看,盘古Ultra在算法、工程、数据各个层面的精细优化下,实现了高效的训练和卓越的性能表现。这一成就不仅展示了华为在AI领域的创新能力,也为未来大规模模型的训练和优化提供了有价值的参考。
原文和模型
【原文链接】 阅读原文 [ 1969字 | 8分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★☆


相关文章



