作者信息
【原文作者】 AI工程化
【作者简介】 专注于AI领域(大模型、MLOPS/LLMOPS 、AI应用开发、AI infra)前沿产品技术信息和实践经验分享。
【微 信 号】 ai-engineering
文章摘要
【关 键 词】 人工智能、多模态框架、视频编码、视频生成、性能评估
腾讯人工智能实验室与悉尼大学在十一月发布了一项最新研究,提出了一种名为GPT4Video的统一多模态框架。该框架不仅能够理解多模态内容,如图片和视频,还能够生成多模态内容,填补了当前多模态大模型在这一领域的空白。
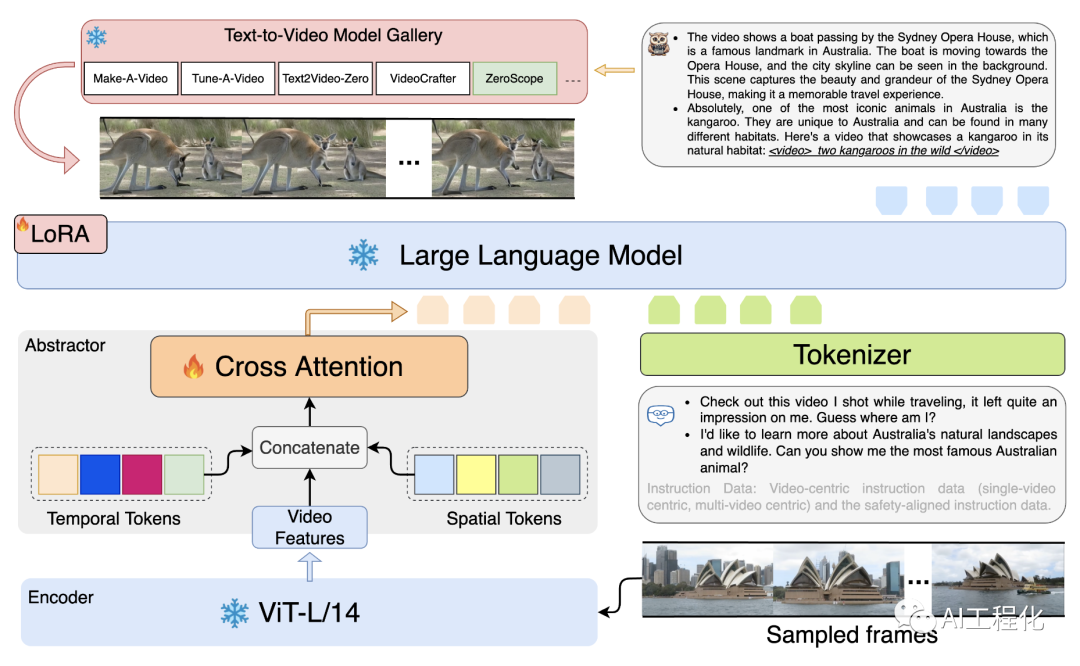
GPT4Video的架构包括三个主要部分:视频编码阶段、LLM推理和视频生成。视频编码阶段采用冻结的ViT-L/14模型捕捉原始视频特征,并通过基于变换器的交叉注意层和两个可学习标记来浓缩信息。LLM推理部分由一个冻结的LLaMA模型驱动,并通过LoRA进行有效微调。最后,LLM生成的提示被用作ZeroScope视频生成模型的文本输入,以创建视频。
GPT4Video在视频理解和生成场景中都表现出了令人印象深刻的能力。它在视频问题解答任务中比Valley高出11.8%,在文本到视频生成任务中比NExt-GPT高出2.3%。此外,GPT4Video使LLM/MLLM具备了视频生成能力,无需额外的训练参数,并能灵活地与各种模型对接。最重要的是,GPT4Video在输入和输出端都能保持安全的对话。
定性和定量实验证明,GPT4Video有潜力成为一个有效、安全、类似人形机器人的视频助手,能够处理视频理解和生成场景。
原文信息
【原文链接】 阅读原文
【原文字数】 570
【阅读时长】 2分钟
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...



