文章摘要
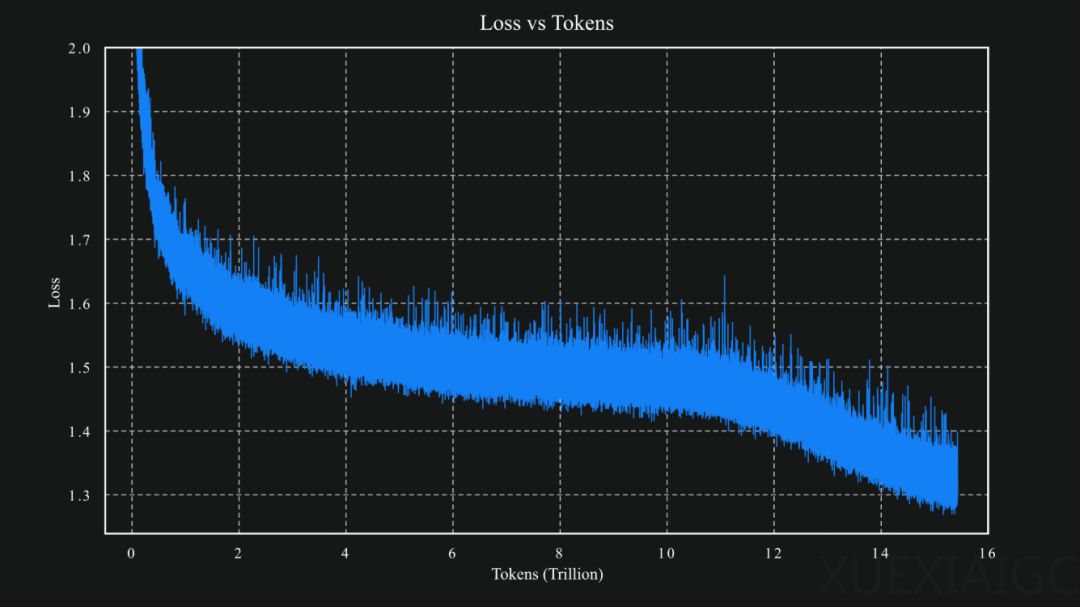
月之暗面(MoonshotAI)近期开源了其最新的大模型Kimi-K2,这是一个混合专家模型,总参数达到1万亿,其中320亿参数处于激活状态,训练数据规模高达15.5Ttoken。Kimi-K2提供了基础和微调两种模型,特别针对AIAgent进行了优化,使其在工具使用方面表现出色,能够帮助开发者打造特定领域的智能体。根据月之暗面公布的测试数据,Kimi-K2在多个基准测试中均表现优异。在SWE-bench的单次测试中,Kimi-K2以65.8分的成绩远超DeepSeek的V3-0324模型(38.8分)和OpenAI的GPT-4.1模型(54.6分)。在多语言测试中,Kimi-K2同样以47.3分的高分领先于V3-0324的25.8分和GPT-4.1的31.5分。在LiveCodeBenchv6代码测试中,Kimi-K2以53.7分超过了所有开闭源模型。在工具使用和数学能力测试中,Kimi-K2也分别以66.1分和49.5分的成绩超越了其他模型。
Kimi-K2的应用场景广泛,例如可以利用其强大的数据分析能力,自动分析复杂的薪资数据,检验远程工作比例对薪资的影响,并通过统计证据和可视化图表展示分析结果。此外,Kimi-K2还可以用于规划演唱会行程,甚至轻松完成复杂的代码任务,如绘制球在六边形中弹跳的动画。
在模型训练流程上,Kimi-K2进行了多项技术创新。预训练是智能体智能的关键基础,Kimi-K2采用了MuonClip优化器,通过qk-clip技术解决了训练中注意力logits爆炸的问题,确保了大规模LLM训练的稳定性。增强智能体能力主要来自两个方面:一是大规模智能体数据合成,借鉴ACEBench开发了全面的管道,模拟真实世界的工具使用场景,生成高质量的训练数据;二是通用强化学习,解决了在具有可验证和不可验证奖励的任务上应用RL的挑战,模型通过自我判断机制为不可验证任务提供反馈,并利用可验证奖励不断更新评判标准。
Kimi-K2还开发了一个全面的管道,灵感来源于ACEBench,能够大规模模拟真实世界的工具使用场景。该方法系统地演化了包含数千种工具的数百个领域,生成了具有多样化工具集的数百个智能体。所有任务都基于评分标准进行评估,智能体与模拟环境和用户智能体进行交互,创建出真实的多轮工具使用场景。一个LLM评委根据任务评分标准评估模拟结果,筛选出高质量的训练数据。这种可扩展的管道生成了多样化、高质量的数据,为大规模拒绝采样和强化学习铺平了道路。
通用强化学习系统采用自评判机制,模型充当自己的批评者,为不可验证任务提供可扩展的、基于评分标准的反馈。同时,使用具有可验证奖励的在线策略回放来持续更新批评者,使其能够不断提高对最新策略的评估准确性。这可以看作是利用可验证奖励来改进不可验证奖励估计的一种方式。
原文和模型
【原文链接】 阅读原文 [ 1202字 | 5分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-v3
【摘要评分】 ★★★☆☆


相关文章




