文章摘要
【关 键 词】 AI发展、合成数据、机器学习、自然语言处理、模型评测
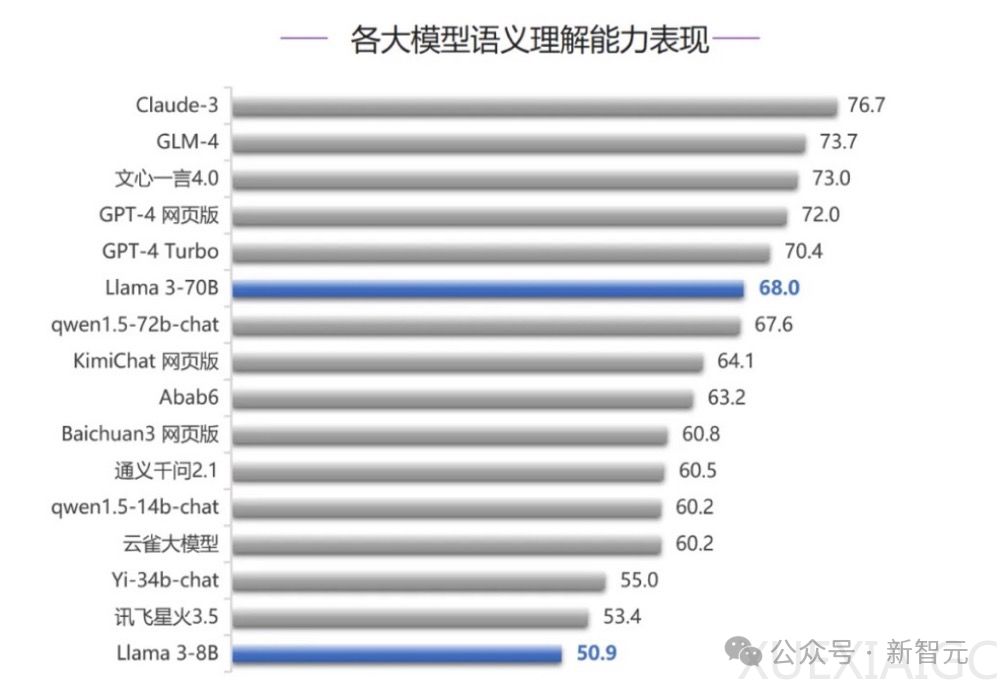
清华大学SuperBench团队最近发布了新一轮的全球大模型评测结果。在语义理解、智能体能力和代码能力三个测评中,Claude 3模型表现出色,拿下两个第一名,并在所有测评中稳居前三。技术报告显示,Claude 3是在合成数据上训练的,这引发了关于合成数据是否代表未来AI发展的讨论。
合成数据,即由机器而非人工生成的数据,在自然语言处理(NLP)和机器学习(ML)领域有着悠久的历史。它与数据增强紧密相关,后者通过细微调整数据来丰富数据集的多样性。在NLP中,一个经典应用是回译,即利用ML模型的输出重新翻译原始文本,生成新数据。
合成数据的重要性日益增加,因为它可以减少人类介入,使AI更符合预期并更用户友好。Anthropic的训练方法和OpenAI的超对齐团队是推动合成数据使命的两大力量。此外,合成数据已成为许多知名开源模型供应商微调Meta和Mistral模型的首选工具。
尽管当前或下一代模型可能已用尽互联网上所有高质量数据源,但合成数据的支持者认为,增加更多数据将有助于模型更好地解决长尾任务或评估问题。为了使模型扩大100倍,将需要大量合成或数字化数据。然而,反对者认为,由于所有生成的数据都来自与当前SOTA模型相同的分布,因此不太可能推动技术产生新的进展。
开源领域在开发各个阶段复制GPT-4和GPT-4-Turbo等数据方面仍有很长的路要走。开源支持者和HuggingFace Hub上的大多数趋势模型都将合成数据作为一种快速发展的方式,并尝试业内最先进SOTA语言模型背后的技术。像Anthropic和OpenAI这样的公司使用合成数据,因为这是他们在规模和能力上取得进展的唯一方式,而小模型之所以使用合成数据,是因为相同规模的人类数据的成本要高出数千倍。
合成数据可以让模型在训练中多次看到某些不常见的数据点,从而提高模型的鲁棒性。通过投喂大量数据,模型在处理小众事实、语言和任务的能力也将显著提高。Anthropic的CAI技术是迄今为止已知最大规模的合成数据应用实例。CAI通过两种方式利用合成数据:1) 对指令调整数据进行评估,确保其遵循一系列原则;2) 利用语言模型生成成对偏好数据,评估在特定原则指导下哪个答案更为恰当。
在开源模型中,合成数据应用方式的演进清晰可见。2023年初,模型如Alpaca和Vicuna通过使用合成指令数据对Llama模型进行监督式微调(SFT),在7-13B参数规模上实现了显著的性能提升。如今,合成偏好开始出现,主要是通过评分或比较哪个更好来实现。最新的进展是通过AI评论生成的偏好或指令数据。
尽管原始的ChatGPT模型(GPT-3.5-turbo)在执行某些任务时会遇到困难,但最新的模型已经能够轻松应对。当开源模型能够稳定地生成评论时,将迎来另一个转折点。目前尚不完全清楚评论数据相比通用偏好评分对于模型的改进有多重要,但如果以Claude为例,它肯定是有用的。
最后,文中提供了两个合成数据的小窍门:1) 始终使用最优的模型来生成数据,因为模型的效果完全依赖于数据的质量;2) API会发生变化,因此需要尽可能锁定版本,以避免研究结果出现重大偏差。
原文和模型
【原文链接】 阅读原文 [ 3006字 | 13分钟 ]
【原文作者】 新智元
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




