文章摘要
【关 键 词】 强化学习、PRIME算法、隐式奖励、数学能力、效率提升
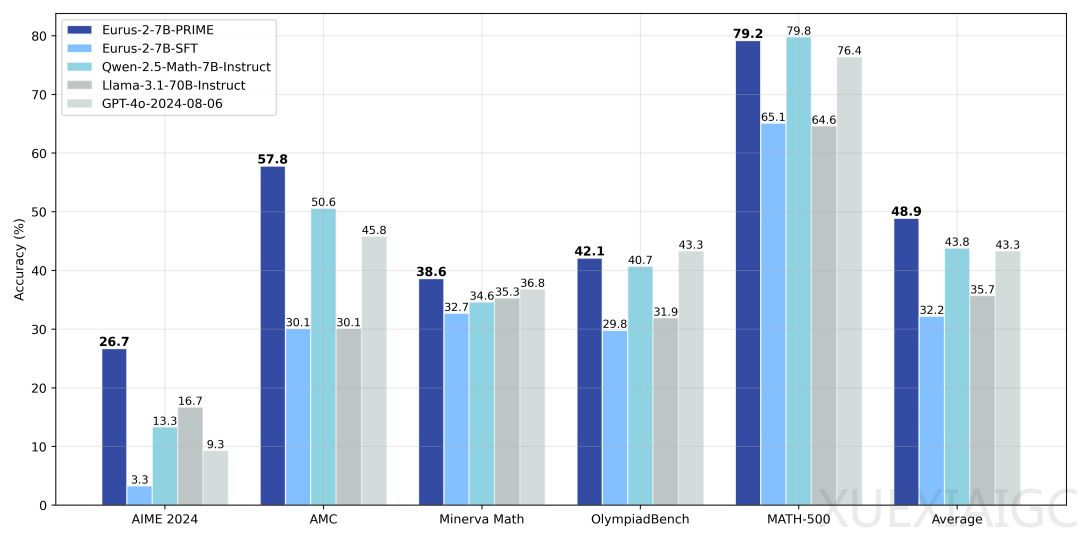
清华大学NLP实验室联合上海AI Lab、清华大学电子系及OpenBMB社区提出了一种新的强化学习方法PRIME(Process Reinforcement through IMplicit REwards),该方法不依赖蒸馏数据和模仿学习,通过隐式过程奖励模型,仅用8张A100显卡、花费约一万块钱、不到10天时间,就训练出一个数学能力超过GPT-4o、Llama-3.1-70B的7B模型Eurus-2-7B-PRIME。PRIME算法利用Qwen2.5-Math-7B-Base作为基座模型,在美国IMO选拔考试AIME 2024上的准确率达到26.7%,大幅超越GPT-4o、Llama3.1-70B和Qwen2.5-Math-7B-Instruct,且仅使用了Qwen Math数据的1/10。PRIME为模型带来了16.7%的绝对提升,远超已知的任何开源方案。
PRIME算法从隐式过程奖励的思想出发,解决了强化学习中如何获得精准且可扩展的密集奖励、如何设计可以充分利用这些奖励的强化学习算法的挑战。隐式过程奖励模型可以仅在输出奖励模型的数据上进行训练,而隐式地建模过程奖励,最终自动训练出一个过程奖励模型,整个过程都有严格的理论保证。PRIME算法具有过程奖励、可扩展性和简洁性三大优势,无需训练额外的价值模型,只需结果标签即可在线更新,有效缓解分布偏移与可扩展性问题。
实验结果表明,PRIME算法相比于仅用结果监督,有着2.5倍的采样效率提升,在下游任务上也有着显著提升。研究人员还验证了PRM在线更新的重要性,在线的PRM更新要显著优于固定不更新的PRM,这也证明了PRIME算法设计和合理性。此外,研究人员还额外收集数据,基于Qwen2.5-Math-Instruct训练了SOTA水平的EurusPRM,能够在Best-of-N采样中达到开源领先水平。
PRIME算法创新性地将隐式过程奖励与强化学习结合,解决了大模型强化学习的奖励稀疏问题,有望推动大模型复杂推理能力的进一步提升。未来基于PRIME方法和更强的基座模型有潜力训练出接近OpenAI o1的模型。
原文和模型
【原文链接】 阅读原文 [ 1268字 | 6分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆


相关文章


