清华、华为等提出iVideoGPT:专攻交互式世界模型
文章摘要
【关 键 词】 生成模型、视频预测、交互式学习、多模态信号、迁移学习
近年来,生成模型在视频生成领域取得了显著进展,尤其在无监督方式学习以构建预测世界模型方面。这些模型能积累关于世界如何运作的常识性知识,并预测智能体的行为潜在结果。利用这些世界模型,基于强化学习的智能体可以更安全、有效地学习新技能。
然而,视频生成模型和智能体学习模型之间存在差距,主要挑战在于如何在交互性和可扩展性之间取得平衡。现有世界模型多使用循环网络架构,但在大规模复杂数据上的建模能力有限。而视频生成模型可以合成逼真长视频,但轨迹级交互性不足。
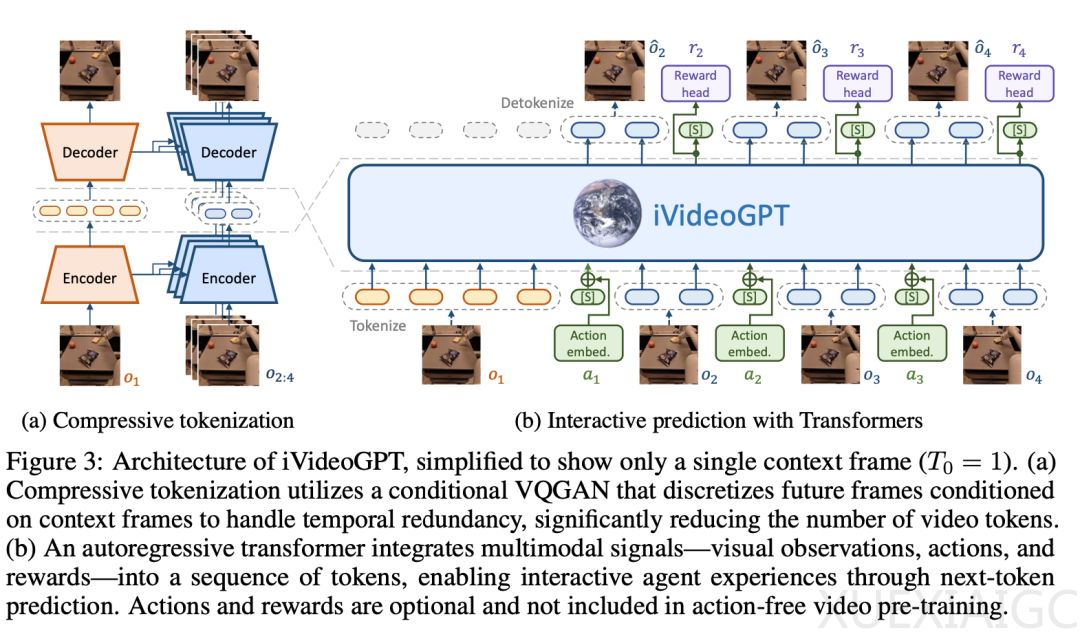
为了解决这一问题,清华大学等机构提出了iVideoGPT,这是一个可扩展的自回归Transformer框架,能集成多模态信号进行交互式视频预测。iVideoGPT采用压缩tokenization技术离散化视频帧,并在多样化数据上预训练,建立交互式世界模型。该研究促进了交互式通用世界模型的发展。
iVideoGPT的核心是一个压缩tokenizer和一个自回归transformer。Tokenizer使用条件VQGAN对视频进行token化,显著减少序列长度,并保持时间一致性。Transformer通过next-token预测进行交互式视频预测。该模型在大量机器人操作视频上预训练,学习物理世界知识。
在微调阶段,iVideoGPT整合动作和奖励预测进行多任务学习,并对tokenizer进行适应以适应下游任务。实验结果显示,iVideoGPT在交互性和可扩展性上具有竞争力,并在下游任务中展现了迁移学习优势。
这项工作促进了通用交互式世界模型的发展,为基于模型的强化学习开辟了新方向。
原文和模型
【原文链接】 阅读原文 [ 3122字 | 13分钟 ]
【原文作者】 机器之心
【摘要模型】 glm-4
【摘要评分】 ★★★★★


相关文章



