文章摘要
【关 键 词】 AI模型、算力消耗、性能争议、数据瓶颈、边际效应
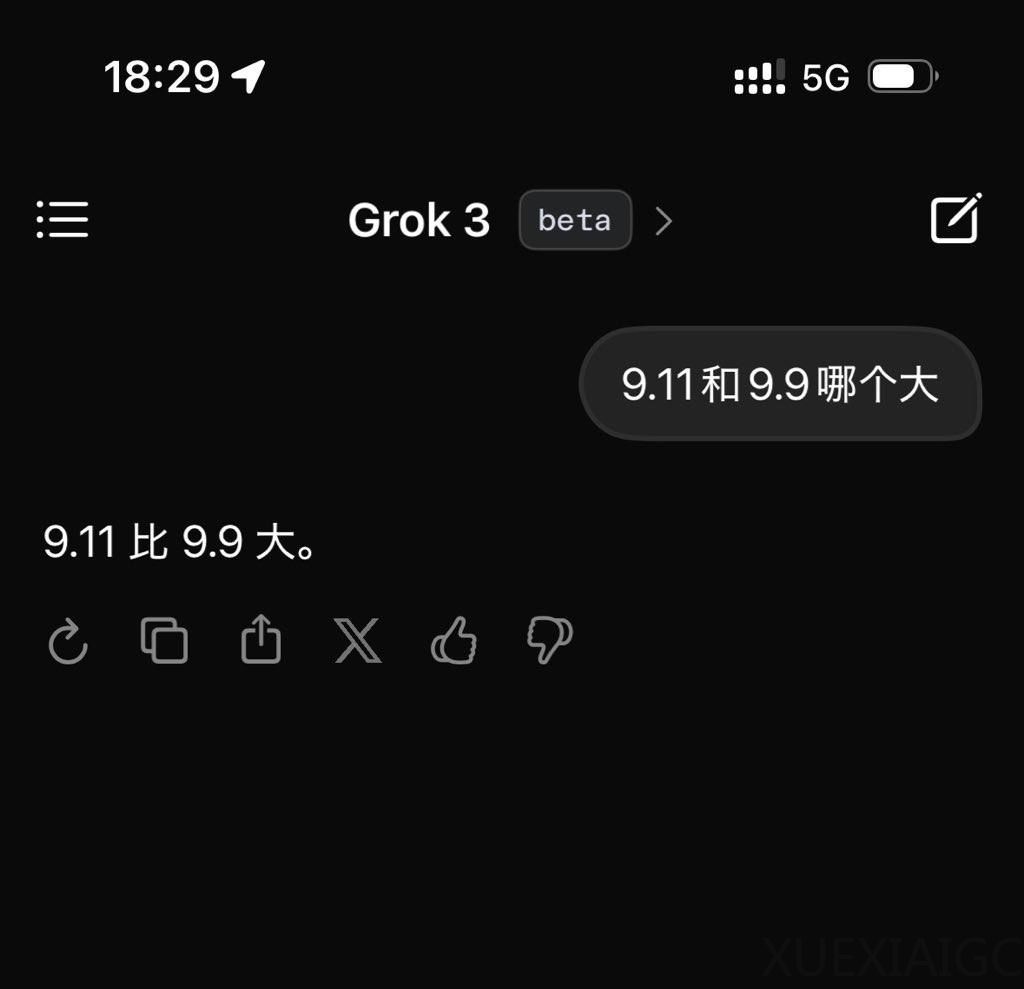
马斯克与xAI团队发布的Grok3模型在基准测试中宣称超越主流AI系统,但其实际表现引发广泛质疑。在基础数学与物理问题测试中,Grok3未能正确回答”9.11与9.9大小比较”及”比萨斜塔双球下落顺序”等常识性问题,暴露出模型对简单逻辑的理解缺陷。直播演示中,Grok3对游戏《流放之路2》的职业数据分析出现大量错误,进一步削弱了其可靠性主张。
尽管官方PPT展示Grok3在Chatbot Arena榜单中”遥遥领先”,但数据显示其仅比DeepSeek R1和GPT4.0高出1-2%。这种微小差距被质疑通过纵轴刻度设计刻意放大,且实际用户体验反馈”无明显差异”。更关键的是,Grok3消耗了26.3万张H100 GPU的训练资源,算力成本达到DeepSeek V3的263倍,但性能提升与投入严重不成比例,凸显大模型训练的边际效应困境。
训练数据瓶颈问题同样显著。即使依托X平台的海量数据,Grok3仍面临与OpenAI类似的优质数据枯竭挑战,导致模型能力提升触及天花板。这种现象印证了Ilya Sutskever关于”预训练模型时代将终结”的预言——当互联网人类生成内容耗尽后,依赖数据扩张的路径将难以为继。行业开始探索新方向,例如通过微调特定数据集实现高效训练,或开发具备自主推理能力的下一代AI系统。
Grok3的争议揭示了当前AI发展的深层矛盾:参数规模与算力堆砌带来的性能增益逐渐衰减,而基础逻辑能力的缺失成为制约实用化的关键短板。这种现状促使研究者重新审视技术路线,从单纯追求模型体量转向探索更接近人类认知机制的学习范式。未来,如何在有限数据条件下突破智能边界,或将成为决定AGI实现进程的核心命题。
原文和模型
【原文链接】 阅读原文 [ 2232字 | 9分钟 ]
【原文作者】 极客公园
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★☆


相关文章




