文章摘要
【关 键 词】 分隔符压缩、注意力机制、KV缓存、训练加速、流式处理
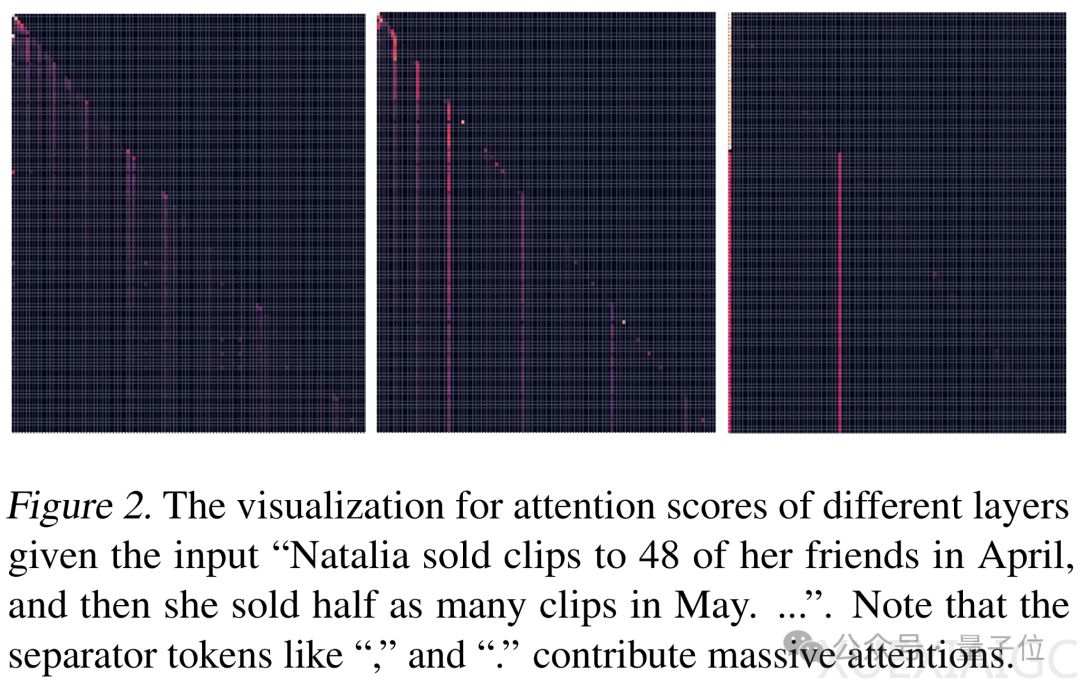
华为、港大等机构的研究团队提出了一种基于自然语言分隔符的新型大语言模型SepLLM,通过将文本语义信息压缩至标点符号中,显著提升了训练推理效率。该方法发现逗号、句号等分隔符在注意力机制中承担着超出预期的信息承载作用,其注意力得分远高于普通语义词汇。这种特性使得模型可将文本段落的信息浓缩至分隔符,从而在保持精度的同时减少KV缓存需求。
传统稀疏注意力方法存在用户提问依赖性强、训练推理流程割裂等问题,而SepLLM基于自然语言内在的段落分隔特性,设计了包含初始token、分隔符token和相邻token的三元注意力机制。在训练阶段强制模型通过分隔符吸收其分割段落的核心语义,生成阶段仅需保留分隔符对应的KV缓存。这种机制使得Llama-3-8B模型在GSM8K和MMLU基准测试中实现超过50%的KV缓存削减,同时保持原有性能水平。
SepLLM架构在流式处理场景展现出独特优势,通过初始缓存、分隔符缓存等四个专用模块的动态管理,可稳定处理超过400万tokens的超长序列。实验数据显示,该方法不仅降低推理时显存压力,还使生成速度提升20%-30%,语言模型困惑度降低15%-20%。在训练效率方面,预训练阶段达到相同loss的时间缩短1.26倍,训练吞吐率提升1.53倍。
该方法展现出广泛的模型适配能力,兼容Llama、Falcon、GPTNeoX等多种架构,参数量覆盖160M至40B区间。动态语义分割机制相比固定区间划分方法,在下游任务准确率上提升3%-5%。研究团队已开源包含分布式训练支持和加速模块的完整代码库,提供融合算子优化方案,为大规模语言模型的高效部署提供新思路。
原文和模型
【原文链接】 阅读原文 [ 2148字 | 9分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★☆


相关文章




