文章摘要
【关 键 词】 视觉理解、开源模型、多模态、AI视觉Agent、性能提升
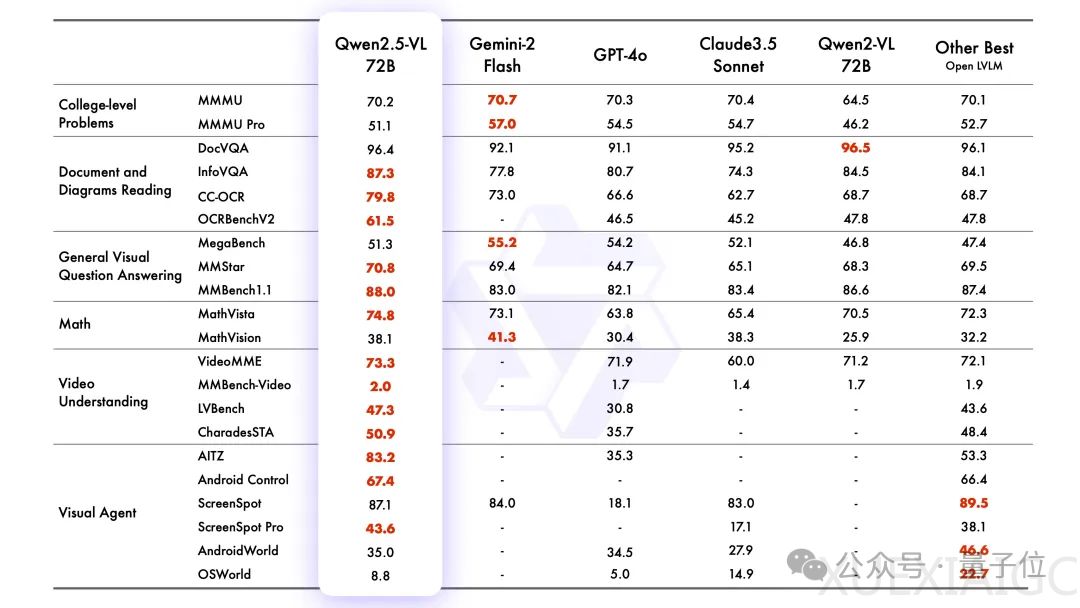
阿里巴巴集团旗下的通义Qwen发布了新的视觉理解模型Qwen2.5-VL,这是一个开源的视觉语言模型,包含3B、7B和72B三个版本。Qwen2.5-VL-72B-Instruct在多个领域的基准测试中表现出色,而7B模型Qwen2.5-VL-7B-Instruct在多个任务中超越了GPT-4o-mini。Qwen2.5-VL在理解文档和图表方面表现突出,且作为视觉Agent操作时无需特定任务的微调。该模型已全系列开源。
Qwen2.5-VL的能力涵盖六个方面:视觉定位、通用图像识别、文档解析、操作电脑和手机的视觉Agent、视频理解和文字识别与理解能力。在视觉定位方面,Qwen2.5-VL能够采用矩形框和点的方式对物体进行定位,并输出层级化的JSON格式。在图像识别方面,模型识别类别得到扩展,包括动植物、地标、影视IP和商品。文档解析方面,Qwen2.5-VL采用QwenVL HTML格式,能够精准识别文档中的文本和元素位置信息,还原版面布局。作为视觉Agent,Qwen2.5-VL能够执行手机、网络平台和电脑上的任务。视频理解方面,模型支持超长视频理解,并具备秒级事件定位能力。文字识别和理解能力方面,Qwen2.5-VL提升了OCR识别能力,增强了多场景、多语言和多方向的文本识别和定位能力。
与前代Qwen2-VL相比,Qwen2.5-VL增强了对时间和空间尺度的感知能力,并简化了网络结构以提高效率。在时间和图像尺寸感知方面,Qwen2.5-VL能够动态转换不同尺寸的图像为不同长度的token,并使用图像实际尺寸表示检测框和点等坐标。在时间维度上,引入动态FPS训练和绝对时间编码,学习时间节奏。视觉编码器方面,Qwen2.5-VL从头开始训练了一个原生动态分辨率的ViT,并引入窗口注意力机制减少计算负担。Qwen2.5-VL的主要特点包括视觉理解、Agent能力、长视频和事件理解、视觉定位和结构化输出。
Qwen2.5-VL全系列已在抱抱脸、魔搭社区开源,Qwen Chat官网可直接体验Qwen2.5-VL-72B-Instruct。Qwen团队计划进一步提升模型的问题解决和推理能力,并整合更多模态,以实现处理多种输入类型和任务的综合全能模型。
原文和模型
【原文链接】 阅读原文 [ 2202字 | 9分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★☆


相关文章



