文章摘要
【关 键 词】 大模型、AI应用、成本效率、技术创新、市场竞争
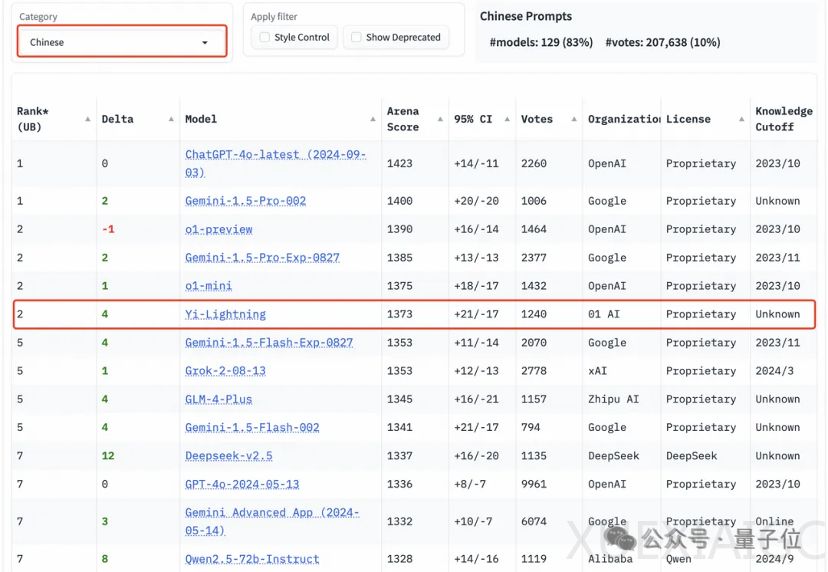
零一万物公司在国际大模型竞技场榜单上取得了突破性进展,其最新旗舰模型Yi-Lightning超越了GPT-4o(5月版本),位列UC伯克利大模型竞技场总榜第6,并以每百万token仅0.99元人民币的价格,显著低于GPT-4o的成本。这一成就标志着中国大模型的强劲增长,并得到了业界的广泛认可。
李开复博士认为,尽管中国大模型创业公司与OpenAI存在5-6个月的差距,但通过独特的“多快好省”策略,可以后发制人,用最少的资源训练出优秀的模型。他强调,中国公司擅长将事情做到极致,低成本高效率的模型能带来更多应用的爆发。
在衡量模型能力方面,李开复博士认为,打榜不仅是为了排名,更重要的是了解在全球竞争中的位置,以及是否还有资格继续前进。UC伯克利大模型竞技场的评估方式因其公平性而受到关注。
随着国内一流模型的成本降低,AI应用进入商业化拐点。李开复博士指出,好的模型推理成本的降低使得AI应用成为可能,尤其是对于ToC市场,他持乐观态度,并认为中国创业者在产品市场匹配方面超过美国。
对于ToB应用,李开复博士认为大模型时代的AI与AI 1.0时代有本质区别,大模型的能力可以更便宜地完成项目,且具有AI 1.0时代所没有的新能力。他提醒ToB创业者要避免一单赔一单的模式,关注解决方案而非模型本身,并找到合适的行业快速融合模型特质。
李开复博士还提到,健康的大模型生态应该是倒三角结构,上层应用最大,底层GPU最小。他观察到,英伟达因其主要客户是超级大厂而赚走了大部分钱,这导致资金流向英伟达,而其他芯片厂商的竞争可能使GPU价格更便宜。
在硅谷的新见闻中,李开复博士提到了大模型技术发展的三条路线:预训练、post-training和推理中加入思考。他还分享了一个经济学教授使用o1模型替代博士生的例子,以及OpenAI融资的挑战和投资人对AI领域的商业评估趋势。
原文和模型
【原文链接】 阅读原文 [ 3638字 | 15分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章



