文章摘要
【关 键 词】 基准测试、区分度、提示词、客观性、验证有效性
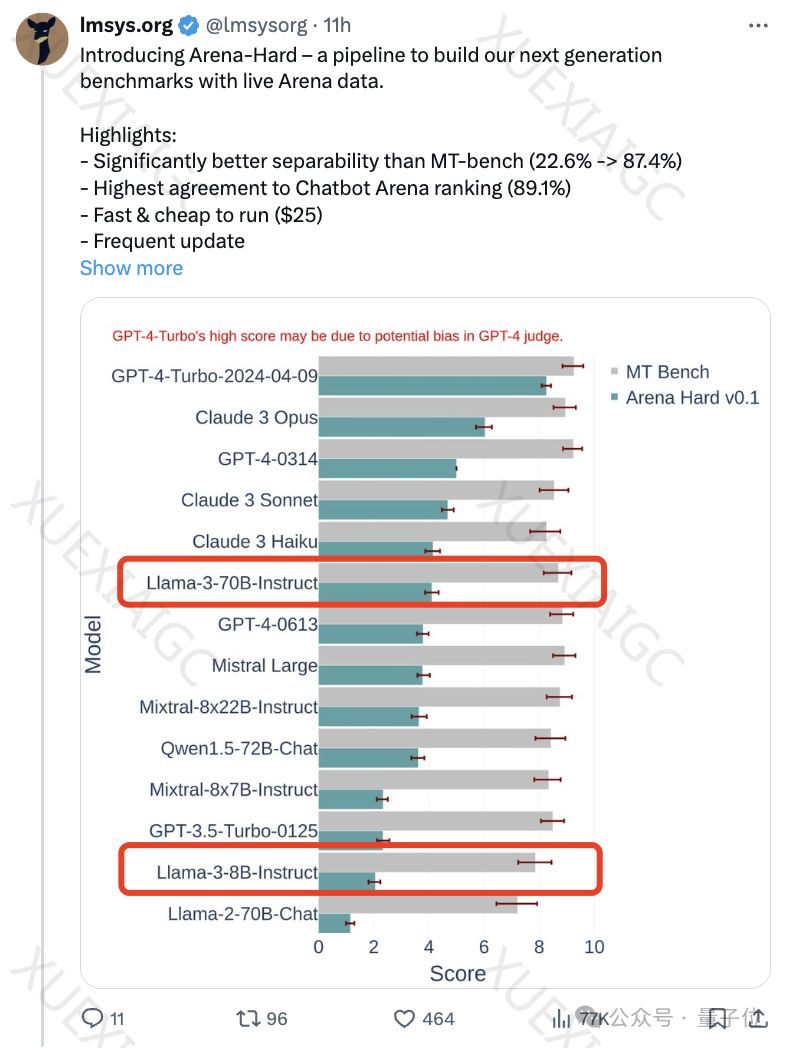
文章介绍了一个名为Arena-Hard的新基准测试,旨在提供更难、更有区分度的测试,以区分不同AI模型的表现。该测试利用竞技场实时人类数据构建,具有高度的区分度和与人类偏好一致率。测试集的选择过程确保了多样性和高质量,通过多个关键指标来衡量提示词的质量。新基准测试的运作方式包括使用大模型竞技场用户查询中的高质量提示词作为测试集,并通过GPT模型对每个提示进行评分。然而,该测试目前存在一个弱点,即使用GPT-4做裁判更偏好自己的输出。研究团队还发现,AI天生会偏好自己的输出,这可能影响测试结果的客观性。团队还进行了消融实验来验证测试的有效性,发现不同提示词对输出结果有不同影响。此外,使用不同大模型来综合打分可能是一个更好的选择。总体而言,新基准测试提供了一个更具挑战性和区分度的测试方式,但仍需要进一步完善和验证。
原文和模型
【原文链接】 阅读原文 [ 1276字 | 6分钟 ]
【原文作者】 量子位
【摘要模型】 gpt-3.5-turbo-0125
【摘要评分】 ★☆☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...



