文章摘要
【关 键 词】 人工智能、学术争议、开源模型、抄袭质疑、知识产权
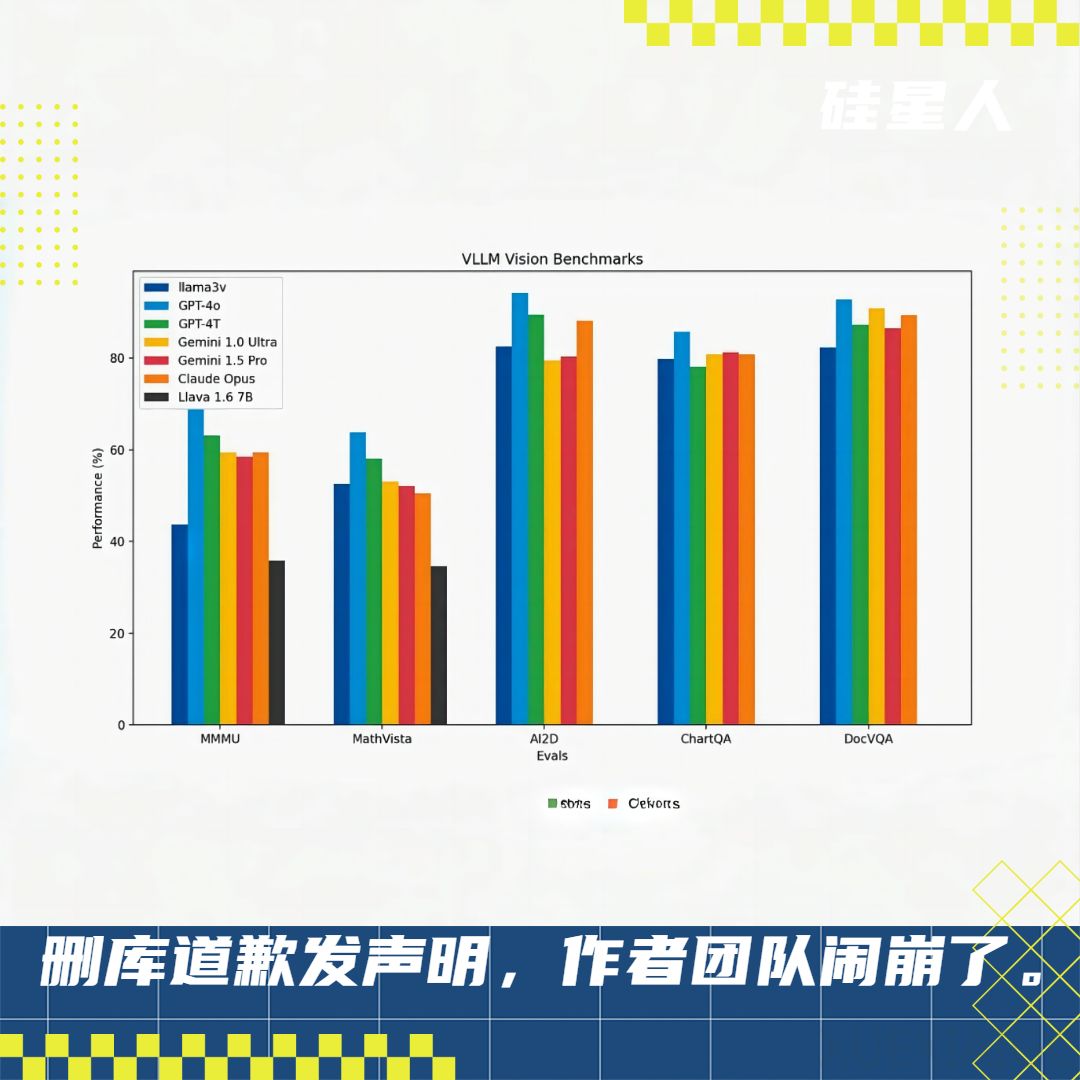
在人工智能领域,一场关于开源大模型的争议近日在学界和社交媒体上引发热议。事件的起因是斯坦福AI团队发布的名为“Llama 3-V”的模型,该模型声称在性能上能够与GPT-4V级别相匹敌,且成本极低。然而,这一模型很快被指出与清华大学自然语言处理实验室及面壁智能合作开发的“MiniCPM-Llama3-V 2.5”模型在结构和代码上存在高度相似性,引发抄袭质疑。
随着事件的持续发酵,Llama 3-V的两名团队成员Aksh Garg和Siddharth Sharma发表道歉声明,表示他们未参与模型的构建,而是仅帮助另一位作者Mustafa Aljadery在社交媒体上推广该模型。他们承认没有做好尽职调查,对比验证以往的研究工作,并为这一失误承担全部责任。
在深入分析中,网友和专家们发现了多项证据,指出Llama 3-V不仅在模型结构和代码上与MiniCPM-Llama3-V 2.5高度相似,而且在技术博客和模型权重中出现了理解错误,这进一步加剧了对抄袭的怀疑。更有力的证据是,Llama 3-V模型展现出了与MiniCPM-Llama3-V 2.5相同的识别中国古文字的能力,这一特殊功能的数据采集和标注是由清华团队内部完成的,外界难以获取。
这一事件不仅反映了学术诚信的重要性,也凸显了开源社区在保护知识产权和鼓励创新方面的挑战。团队成员的道歉并未能有效平息争议,反而引发了更多的批评和讨论,强调了在科研合作中明确责任和透明度的重要性。随着技术的迅速发展,确保学术成果的公正性和原创性成为了一个日益重要的议题。
原文和模型
【原文链接】 阅读原文 [ 4768字 | 20分钟 ]
【原文作者】 硅星人Pro
【摘要模型】 glm-4
【摘要评分】 ★★★★★


相关文章




