文章摘要
【关 键 词】 多模态数据集、MINT-1T、开源资源、数据处理、AIGC研究
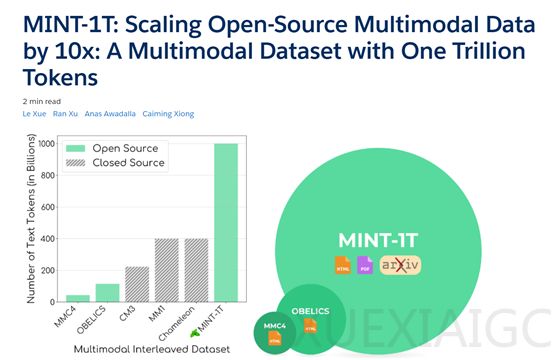
华盛顿大学、斯坦福大学和Salesforce的研究人员联合发布了一个名为MINT-1T的多模态数据集,其规模是现有开源数据集的10倍,包含约1万亿个文本标记和34亿张图像。该数据集的开源地址为https://github.com/mlfoundations/MINT-1T,旨在为开发如GPT-4o、Gemini等多模态模型提供全面和多元化的数据支持。
MINT-1T数据集的来源多样,包括CommonCrawl提供的HTML文档,这些文档经过数据过滤以确保质量和多样性,排除了不包含图像或包含超过三十张图像的文档,同时剔除了图像URL中含有不适当子字符串的文档。团队采用OBELICS方法提取多模态文档,保持了图像和文本的原始顺序。此外,通过Bloom Filter技术进行去重处理,减少了数据集中的冗余内容。
PDF文档是数据集的重要组成部分,来源于CommonCrawl WAT文件,覆盖了2023年2月至2024年4月的数据。研究人员限制了PDF文件的大小和页数,排除了超过50MB或50页的文档,以提高数据处理的效率。
ArXiv网站提供了大量基于LaTeX源代码的专业论文,研究人员从中提取了包含文本内容、图像、表格和参考文献的文档。在处理LaTeX源代码时,识别图形标签并确定图像在文本中的相对位置,以保持文档的原始结构。
在初步处理后,研究人员进一步筛选数据,使用Fasttext模型排除非英语文档,删除包含不良内容的URL,并采用RefinedWeb的文本过滤方法移除低质量文档。在图像过滤方面,丢弃了无法检索的链接和没有有效图像链接的文档,并移除了小于150像素的图像以提高图像质量。同时,对所有图像使用NSFW图像检测器,并进行了个人信息的匿名化处理,以确保数据集的安全性和合规性。
MINT-1T数据集的开发为AIGC领域的研究和应用提供了宝贵的资源,有助于推动多模态模型的发展和市场研究,同时也为AIGC开发者生态的构建提供了支持。
原文和模型
【原文链接】 阅读原文 [ 1102字 | 5分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆


相关文章



