推理性能直逼o1,DeepSeek再次出手,重点:即将开源
文章摘要
【关 键 词】 推理模型、深度思考、强化学习、性能提升、开源承诺
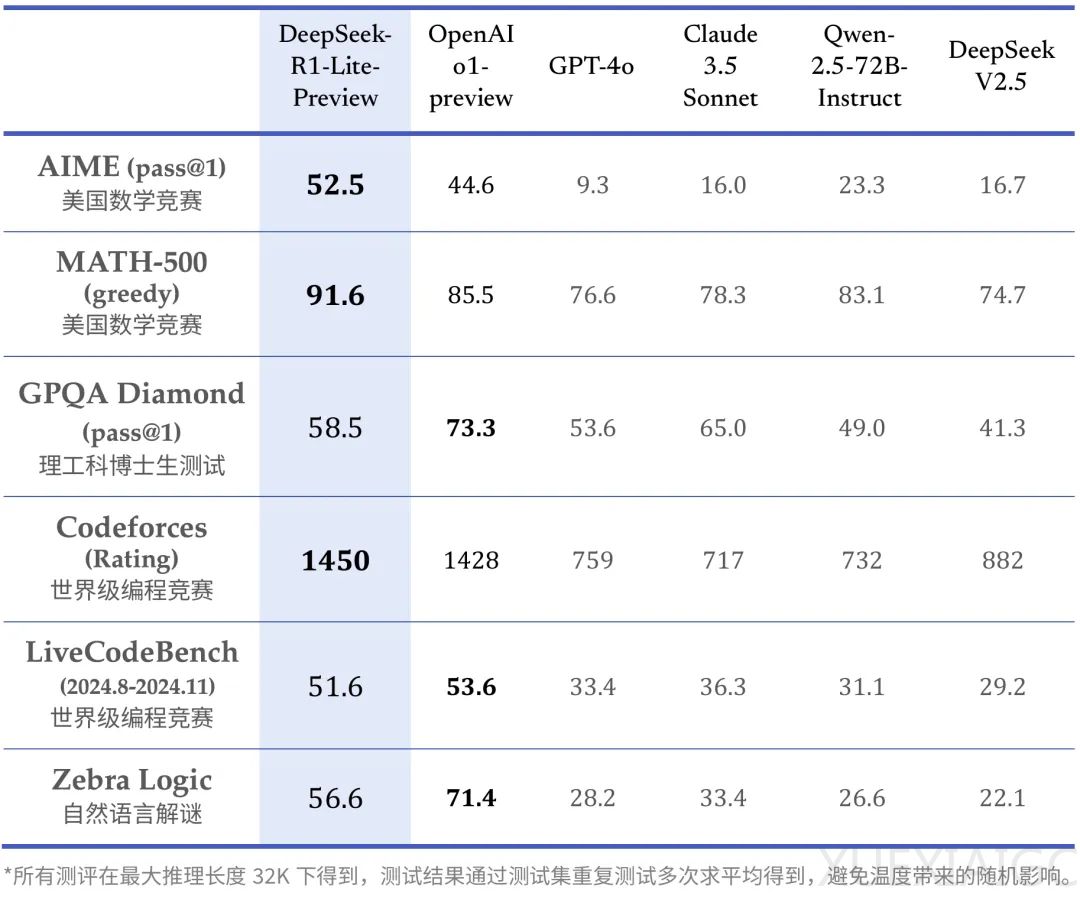
DeepSeek最近推出了一款新的推理模型DeepSeek-R1-Lite-Preview,这款模型在多个权威评测中超越了包括GPT-4o在内的顶尖模型,甚至在某些方面领先于OpenAI o1-preview。DeepSeek-R1-Lite-Preview的关键在于其“深度思考”能力,它通过更多的强化学习、原生思维链和更长的推理时间来提升性能,类似于人类大脑的深度思考过程。与OpenAI o1不同,DeepSeek-R1-Lite-Preview在回复中会展示其“思路链”推理过程,解释其操作的原因。
DeepSeek官方表示,R1系列模型使用强化学习训练,包含大量反思和验证,思维链长度可达数万字。DeepSeek-R1-Lite-Preview使用的是一个较小的基座模型,尚未完全释放长思维链的潜力。用户可以通过官网与DeepSeek-R1-Lite-Preview对话,但需要在输入框中打开“深度思考”模式,每天限制50次使用。
尽管DeepSeek-R1-Lite-Preview目前仅支持网页使用,没有发布完整代码供独立第三方分析或基准测试,也没有通过API提供服务,但DeepSeek已表示正式版DeepSeek-R1模型会完全开源,公开技术报告,并部署API服务。
初步测评显示,DeepSeek-R1-Lite-Preview在回答复杂问题时需要数十秒的“思考”时间,尽管有些思路可能在人类看来无意义或错误,但最终整体准确率较高。例如,它能够回答GPT-4o和Claude系列都翻车过的问题,如“Strawberry”中有多少个字母“R”和“9.11”和“9.9”哪个更大。在中文问题上,DeepSeek-R1-Lite-Preview的准确率更高,能够破解行测题的逻辑陷阱,并在34秒内解决大学物理问题。
然而,DeepSeek-R1-Lite-Preview在数学能力上可能不如推理、物理和编程能力那么强。例如,在一道中学水平的数列题上,它没有想出关键的破题思路,而是“蒙”出了答案。在IMO国际数学奥林匹克竞赛试题上,尽管DeepSeek-R1-Lite-Preview在长达162秒的思考过程中详细地写出了解题思路,但最终答案仍然错误,而OpenAI o1却给出了正确答案。这表明DeepSeek-R1-Lite-Preview仍有进步空间,也让人更加期待完整版模型的发布。
原文和模型
【原文链接】 阅读原文 [ 1489字 | 6分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章




