文章摘要
【关 键 词】 技术突破、商汤科技、语义向量、多任务训练、模型性能
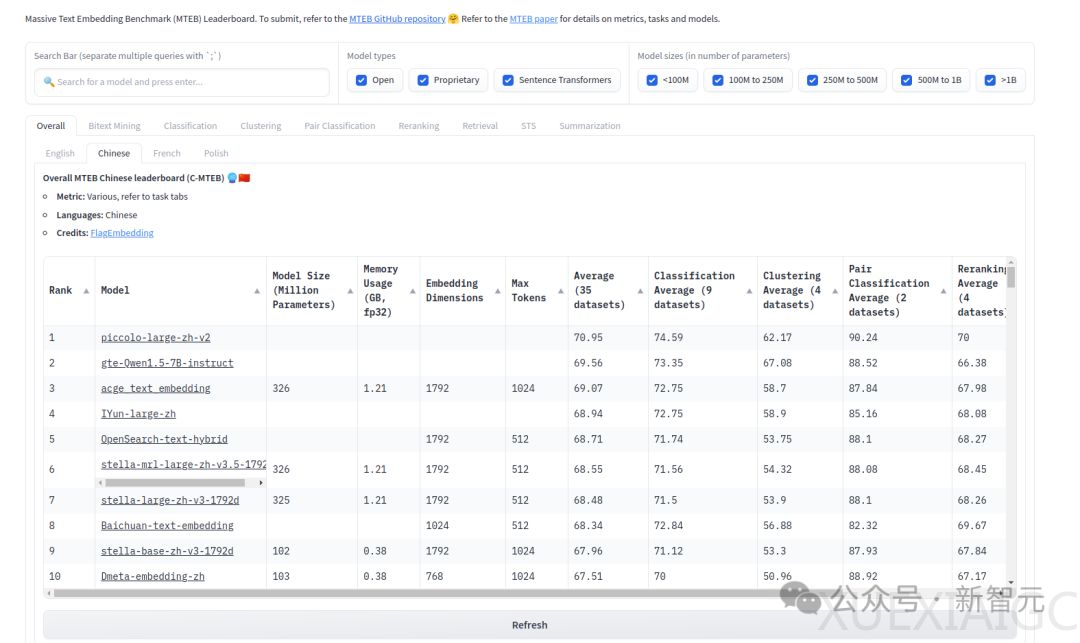
在最新的技术突破中,商汤科技的自研通用Embedding模型Piccolo2已在中文语义向量评测基准C-MTEB中名列第一,成为当前最大规模、最为全面的中文语义向量表征能力评测基准的领先者。该模型支持512/2K/8K三种向量长度,其中8K模型是当前中文Embedding中能够实现对标OpenAI向量长度的模型。
Piccolo2的亮点之一是其多任务混合损失训练方法,该方法适用于不同的下游任务,如检索、句对分类和句子相似度等,通过针对不同任务采用不同的训练损失,显著提升了模型性能。此外,模型利用了高效的数据合成框架和难负样本挖掘方法来不断扩充数据集的数量和质量。
商汤科技的算法和算力提升,以及对嵌入维度的扩大,使得Piccolo2在中文大模型测评基准SuperCLUE中超越了GPT-4 Turbo,并在OpenCompass的基准评测中表现出色。模型在长文本处理和获取信息方面的能力也得到了显著提升,这对于解决大语言模型中的幻觉问题具有重要意义。
受到OpenAI的text-embedding-v3启发,Piccolo2采用了更大的嵌入维度和「套娃学习」(Matryoshka Representation Learning, MRL)技术,支持更灵活的向量维度推理。MRL技术让模型在保持高维向量表征的同时,也能在小维度上展现良好的性能。
通过这些技术创新,Piccolo2在C-MTEB上取得了70.95的平均精度,相比之前的SOTA模型acge-embedding,综合评分提升了约1.9个点。这表明商汤科技的Piccolo2在提供多粒度表达能力的同时,也为开发者们提供了灵活的选择,进一步推动了中文大模型领域的发展。
原文和模型
【原文链接】 阅读原文 [ 2279字 | 10分钟 ]
【原文作者】 新智元
【摘要模型】 glm-4
【摘要评分】 ★★★★★


相关文章


