文章摘要
【关 键 词】 RLHF、OpenAI、模型复现、Pythia模型、训练细节
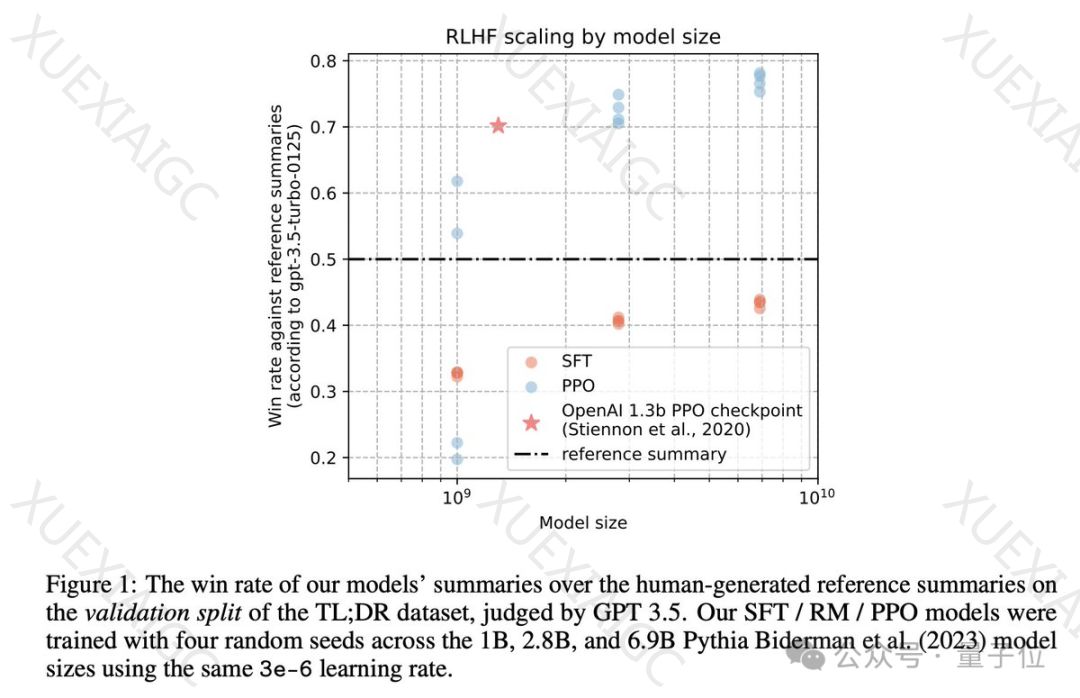
OpenAI的ChatGPT背后的关键技术RLHF(人类反馈强化学习)被Hugging Face等研究机构成功复现并开源。研究人员详细列出了25个关键实施细节,并展示了模型性能随模型大小增加而提升的scaling行为。特别地,2.8B和6.9B的Pythia模型在性能上超过了OpenAI发布的1.3B模型。
研究人员的复现工作选择了OpenAI早期的RLHF工作,即摘要任务,作为研究对象。RLHF包括三个步骤:监督微调(SFT)、奖励模型(RM)训练和强化学习(RL)策略训练。在SFT阶段,研究人员使用Reddit TL;DR数据集进行微调。在RM阶段,基于人类标注员的偏好数据训练模型。在RL阶段,使用PPO算法优化RLHF目标函数。
研究人员在复现过程中注意到了数据预处理、SFT和RM训练的多个细节。例如,在数据预处理阶段,OpenAI采用了特定的截断策略和token填充方法。在SFT阶段,研究人员发现标准的下一个token预测损失足以进行训练。而在RM训练阶段,他们发现RM只在EOS token处提取奖励,并且奖励的logits除了EOS token外几乎都是负数。
在PPO训练阶段,研究人员发现值函数logits通常更为正面,并使用了EOS技巧来处理不以EOS token结束的完成序列。他们还尝试了奖励白化处理,发现这会略微降低与参考摘要的胜率并缩短完成token的长度。通过长度控制分析,研究人员发现PPO模型几乎总是优于SFT模型。
研究人员的工作不仅提供了对OpenAI RLHF技术的深入理解,还通过开源代码和模型checkpoint,为学术界和开发者提供了宝贵的资源。这一成果有助于推动大型语言模型训练方法的进步和开放性。
论文和代码的公开发布,为AI研究社区提供了进一步探索和改进RLHF方法的机会。此外,研究人员的工作展示了开源合作的力量,以及如何通过共享知识和资源来加速技术的发展。随着AI技术的不断进步,此类开源项目对于维持技术发展的透明度和可访问性至关重要。
原文和模型
【原文链接】 阅读原文 [ 2219字 | 9分钟 ]
【原文作者】 量子位
【摘要模型】 gpt-4
【摘要评分】 ★★★★★


相关文章


